
협동 분산 시스템 (1)
건국대학교 협동분산시스템 강의노트
Chapter 1. Introduction
- Two advances in
- powerful microprocessors “무어의 법칙”
- HIgh-speed computer networks
분산시스템 정의
- “분산시스템은 독립적인 컴퓨터들이 모여있는 시스템이다. 사용자에게는 1개의 거대한 시스템으로 보인다.”
- 좋은 품질의 서비스를 제공하기 위해 scalable한 설계.
- Important
- 자율적인 components 로 구성된다.
- 유저들은 하나의 시스템이라 생각한다.
- 분산시스템의 특징
- 여러 컴퓨터의 커뮤니케이션을 유저로부터 숨긴다.
- 유저와 애플리케이션의 Interaction은 일관적이고 균일한 방법으로
- 위치와 장소에 관계 없이.
- ex) A방법 -> X기능, B방법 -> Y기능. 아… 별로다
- 확장이 요이해야한다. 필요할 때 쉽게 확장
- 독립컴퓨터
- 시스템의 확장은 유저로부터 숨긴다.
- 분산시스템은 continuously available
- 몇몇 부분이 죽더라도 서비스는 돌아가야한다.
Middleware
- 분산시스템은 흔히 쓰이는 소프트웨어 layer의 수단.
- 계층적으로 중간에 있는 소프트웨어
+-------------------------------+ | higer-level layer | - user applications +-------------------------------+ ||| ||| +-------------------------------+ | Middleware | +-------------------------------+ ||| ||| +-------------------------------+ | layers underneath | - Operating system +-------------------------------+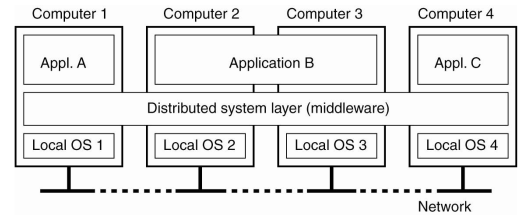
- Middleware는 일종의 라이브러리라고 생각하자.
- 동일한 interface를 제공
- 요청 A -> C: middle api 사용. 서비스요청을 받고 처리까지.
- 사용자입장에서는 분산되어있음을 최대한 숨긴다.
- 그래서 Middleware밑에 필요한 모든걸 숨긴다. interface 역할
- 장점: 사용자에게 편리한 인터페이스.
- 단점: 퍼포먼스가 떨어진다.
Goals
- Making resources accessible
- 사용자에게 리모트 서비스 접근을 쉽게, 편리하게 한다.
- Distribution transparency
- process와 resource가 분산되어 있음을 숨긴다.
- 너무 엄격하게 적용하면 퍼포먼스가 떨어질 수 있다.
- Openness
- 서비스를 표준에 따라 제공하자
- 표준: 데이터를 제공하는 방법, 요청하는 방법의 표준
- 표준만 따르면 누가 만들어도 쉽게 접근 가능.
- Scalability
- 리소스의 사이즈 확장, geographically 확장, administratively 확장 가능한 시스템,
- 리소스의 사이즈: 스토리지, 컴퓨팅 파워 -> 많은 수의 사용자
- geographically 확장: 사용자도 그렇고, 시스템도 그렇고, 다양하게 퍼져있어서 어디서나 동일한 품질의 서비스를 제공받을 수 있다.
- administratively 화장: 운영, 정책적인 측면
- 여러 admin이 있을 때 하나의 서비스를 제공할 수 있다면.
- 운영, 정책적인 문제가 크다.
Making resouce Accessible
- 그룹웨어. 여러 사요자가 리소스를 share하면서 cscw.
- computer-supported collaborative work
- 리모스 액세스 connectivity up.
- security가 점점 더 중요해진다.
Distribution transparency
- 사용자가 서비스를 편하게 이용하기 위해 분산을 숩기는 것이 좋다.
- transparent distributed system
- 분산시스템이 마치 1개의 시스템, 마치 로컬시스템 마냥 이용할 수 있다.
- Access -> 데이터 형태, 제공방식이 다르더라도 액세스 방법이 똑같다면
- Location -> 리소스의 위치를 숨긴다.
- Migration -> 리소스가 이동됐음을 숨긴다. (마이그레이션을 숨긴다.)
- Relocation -> 사용 중 리소스가 이동됐음을 숨긴다.
- Replication -> 리소스가 복제됐음을 숨긴다.
- Concurrency -> 리소스가 공유되고 있음을 숨긴다.
- Failure -> failure, recovery를 숨긴다. fault-tolerant 시스템.
Distribution transparency: Types of transparancys
- Access transparency
- ex) 다양한 os에서 돌아가는 컴퓨터
- 각각 그들의 file-naming 컨벤션이 있다
- 이 네이밍 컨벤션 차이는 유저와 애플리케이션에선 숨겨야한다.
- ex) ppt-> 윈도우, 맥 어디서든 편집, view 가능
- access transparency가 제공된다.
- ex) 다양한 os에서 돌아가는 컴퓨터
- Location transparancy
- 리소스의 위치를 숨긴다.
- URL -> A, B
- Migration transparancy
- 유저가 사용하지 않을때 밤새 데이터가 이동됐다. 유저는 모른다.
- User -> URL (A(Windows) -> B(Linux))
- Relocation transparancy
- 유저가 사용하고 있는데 데이터가 이동됐다.
- 모바일 유저 -> wireless 네트워크 (개념상 relocation)
- 이동중에도 잘 쓸 수 있다.
- Replication transparency
- 리소스 copy를 숨긴다. 리소스 availabilty를 올리기 위해
- ex) 영화 파일 복제 -> 한국 서버, 미국 서버. 유저는 모른다.
- Concurrency transparency
- 각 유저가 다른 유저와 같은 자원을 쓰고 있는 것을 모른다.
- **중요한 이슈는 공유자원에 동시접근을 일관되게. -> 같은 파일을 동시에 edit 한다면?
- concurrency control 필요
- Failure transpareny
- fault-tolerant
- 죽어서 다시 살아나는 걸 숨긴다. backup.
Distribution transparency: Degree of transparency
- 숨기는게 항상 좋은가?
- ex) 전자신문 (적절한 예시는 아니다.)
- 오전 7시에 구독. 그리고 유저가 한국 -> 미국으로 이동했다. (시간대 변경)
- 유저가 서비스에 자신의 위치를 알려야한다.
- 개인정보 이슈
- ex) 분산시스템. 샌프란시스코 <-> 암스테르담.
- 메세지를 35ms안에 보내는 것이 불가능
- 빛의 속도라는 물리적 한계.
- 많이 숨길수록 성능이 떨어진다.
- Trade-off : Degree of trans parency와 Performance
- ex) Internet application retry.
- unavailable retry
- 계속 기다리는 것보다 unavailable을 알려주는게 나을 수도 있다.
- 적당히 숨기는 게 좋다.
- ex) 분산 프린터 시스템
- 놀고 있는 프린터보다 가까이있는 바쁜 프린터가 좋다.
Openness
- 표준 -> 요청방식, 제공방식
- Standard rule에 따라 서비스를 제공하는 시스템
- ex) 포맷, 컨텐츠, 메세지 수단. 컴퓨터 네트워크
- 프로토콜로 정형화 된 rule
- 인터페이스를 통해 특화되는 서비스
- IDL(Interface Definition Language)로 인터페이스를 정의하자.
- Client가 Syntax를 알 수 있다.
- Function name, parameters, return values
- 그 서비스가 자세히 무엇을 하는 지는 모름
- 인터페이스의 Sementics
- Interoperability 상호운용성
- 사용자는 어느 회사에서 만든 서비스건 상관없이 사용이 가능하다. (표준을 이용해서)
- Portability 이식성
- 그대로 옮겨도 이용자에게 손쉽게 전달이 가능하다. 표준을 잘 지킨다.
- ex) JVM
- Another goal
- Configure
- 컴포넌트 추가/대체
Openess: policy과 메커니즘 분리
- 좀 더 flexible한 서비스를 위한 분신시스템 디자인
- 서비스를 얼마나 flexible하게 만들 수 있는가
- 많은 서비스를 보면 모놀리식 (vs. flexbilirt)
- option을 고려하지 않았다.
- ex) 웹브라우저 캐시. 캐싱서비스가 flexible하지 않다면
- 웹브라우저에서 캐시 사이즈, consistency 체크, 데이터 신선도 정책 설정 가능
- 유저는 다른 패러미터 configure는 안된다. (얼마동안 캐시할건지, 캐시가 다 차면 어떤 문서가 삭제될 건지)
- 메커니즘: 서비스 그 자체
- ex) Web caching
- parameter를 제공해야 한다.
- ex) Web caching
Scalability 확장성
- 가장 중요한 목표
- Measurement
- size
- 유저와 리소스를 쉽게 추가할 수 있다.
- geographically
- 유저와 리소스가 멀어질 수 있다.
- administratively
- 관리가 쉽다.
- 다는 못하니 3개중 2개.
- size
Scalability: Problems (with the size)
- 중앙집중 서비스, 데이터, 알고리즘 제한
- 중앙집중 서비스
- 병목, 무제한 프로세스, 스토리지 용량이 있어도 컴니케이션 이슈
- DDoS 서버렉
- 중앙집중 데이터:
- SPoF
- ex) 5천만명의 핸드폰 번호
- 중앙집중 알고리즘
- single machine에서 돌아가는 알고리즘은 피해야한다.
- 분산알고리즘 써야한다.
- 분산 알고리즘 특징
- 어떤 머신은 시스템에 대한 완전한 정보를 모른다.
- 내가 갖는 input만 갖고 result를 만든다. 컴포넌트 분산
- 결과는 local information 기반
- 머신 하나의 failure가 시스템을 망가트리진 않는다.
- 분산 알고리즘은 optimal하지 않다.
- 최적의 결과는 아니지만, 최적에 근접한, 빨리 solution을 찾는 needs.
- 모든 서버의 clock sync를 맞춰야 한다.
- 동기화를 해야한다.
- communication delay issue.
- 피하기 위한 방법?
- 어떤 머신은 시스템에 대한 완전한 정보를 모른다.
Scalability: Problems (with Geography)
- Synchronous Communication -> delay. 물리적으로 멀리졌을 때 delay는?
- node <-> node
- 분산시스템은 분산 communication
- client가 reply가 올때까지 block. sync
- <-> async. 기다리면서 딴짓. delay 에서 이득.
- WAN에서 Communication은 선천적으로 unreliable
- Virtually always point-to-point
- 버퍼가 가득차면 새로오는 메세지는 버린다. packet drop.
- 그래서 TCP를 쓴다. 없어지면 다시 보내도록.
- ex) 분산시스템 서비스를 쓰려면 어떤 서비스가 있는지 알아야한다.
- 어떻게 알아?
- Broadcast는 WAN에선 쓰면 안된다.
Scalability: Problems (with the administration)
- 기술적인 것보다 어렵다.
- 통신사별 같은 서비스라면?
- 1개의 분산 시스템, 여러 회사의 조직
- Security 이슈
Scalability: scaling techniques. 스케일링 기법
- 3개의 기법
- Communication atency를 숨긴다.
- 어떻게? 제일 빨라야 빛의 속도
- 메세지를 보낼 필요가 없게 만든다.
- Distribution
- Replication
- centralized data 이슈를 기억하자. 데이터를 분산시키고, 복제시켜놓자.
- Communication atency를 숨긴다.
- Hiding communication latency
- 요청해서 결과가 오기까지 시간을 줄여보자
- Sync vs Async
- Async: 데이터를 요청하며 다른 task를 한다.
- 다른거 할게 없으면… 의미 없다
- 가능한한 횟수를 줄이자.
- local에서 할 수 있으면 local에서. 필요한 경우 client에서.
- 자바 애플릿과 자바스크립트
- ex) 이메일, 입력폼, 데이터
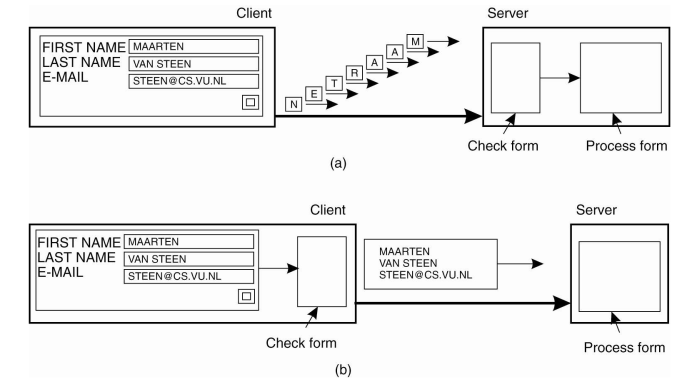
- 입력시 포맷확인
- 클라이언트 데이터 -> 서버
- 서버에서 하던거를 클라에서 하자.
- 요청해서 결과가 오기까지 시간을 줄여보자
- Distribution. 전체리소스를 쪼개서 흩뿌린다.
- 컴포넌트
- 작은 파트로 쪼개라
- 그 부분을 시스템 전체로 퍼트리자.
- 좋은 예
- Domain Name System
- DNS (replication도 사용한다.)
- 전세계적으로 서버가 여러대.
- 계층적 구조
- Single name server -> each zone
- SPoF도 피할 수 있다.
- 다른 예 (WWW)
- web contents 분산.
- Replication
- 서버가 1개밖에 없으면 load가 많이 걸린다. 죽으면?
- 분산, 복제 이슈는 동일
- 장점
- 리소스 availabilty up
- 로드 밸런스 (컴포넌트 사이에서)
- 더 좋은 성능
- geographically widely-dispersed system
- 커뮤니케이션 latency를 숨기기 좋다. (어디에서든 접근)
- 캐싱: Special form of replication
- 클라이언트에서 결정. (다음에도 또 쓸까봐)
- 보통 Replication은 서버측에서 복제를 결정
- 시점: on demand
- 보통 Replication은 사전에 복제. (사용자가 요청하기 전에)
- 클라이언트에서 결정. (다음에도 또 쓸까봐)
- Consistency problems (단점)
- 일관성 문제. (복제된 것들 사이에서 일관성 원본 + 복제)
- 원본이 업데이트 되었을때 복제가 갱신되어 있지 않다면?
- 정책.
- ex) 학과홈페이지 -> 별로 업데이트되지 않는다. -> consistency 정책 1일… 2일…
- ex) 주식 -> 복제된 데이터도 critical. 매번 바뀌는 데이터. -> 계속 consitency 체크. 1분? 1초?
- 정책.
- 동시에 2개의 update
- 충돌 이슈.
- sync 메커니즘 필요
- 종합
- 사이즈 측면이 가장 쉽다.
- 기술적인 관점에서 가장 문제가 안된다.
- Distribution, replication, 그리고 caching 다같이 쓴다.
- Administrative 가 가장 어렵다.
- 기술적이지 않은 부분을 해결해야 한다.
- 사이즈 측면이 가장 쉽다.
Pitfalls
- 쉽게 빠지는 함정
- 가정
- The network is reliable -> TCP로 하면 좀 낫다.
- The network is secure
- The Network is homogeneous -> 동일한 아키텍쳐의 network를 쓴다?
- The topology does not change -> 모바일 디바이스는 항상 위치가 바뀐다.
- Latency is zero -> 딜레이 이슈
- Bandwidth is infinite -> 대역폭은 상황에 따라 달라진다.
- Transport cost is zero -> 전송비용. 상황에 따라 달라진다.
- There is one administrator
Types of distributed Systems
- Distributed computing systems
- 컴퓨팅 파워
- 시스템은 CPU가 좋다.
- 공학 시뮬레이션, 입자물리 등
- Distributed information systems
- 정보제공.
- 여러가지. www, 데이터, 게임
- Distributed pervasive systems
- 센서데이터, 환경이 dynamic.
- 임베디드, 모바일
Chapter 2. Architectures
- 디자인 시 어떤 부분을 고려해야 하는가.
- 분산시스템에서 소프트웨어 컴포넌트를 어떻게 구성해야 하는가.
- 주로 서버단에서.
- 소프트웨어를 어떤 구조로 만들 것인가.
- Goal
- 분산시스템 애플리케이션과 underlying platform 분리
- OS… 하드웨어 리소스… 애플리케이션이 돌아가는 환경은 다양할 수 있다.
- Separation을 위해 미들웨어.
- Distribution transparency
- Adaptability - 상황에 맞게 적응할 수 있는 시스템
- 사용자 취향에 맞는 서비스
- 상황에 따라서 변화된 서비스에 맞게
- 분산시스템 애플리케이션과 underlying platform 분리
Architectural Styles
- 스타일? 어떤 부분에서 차이? -> 컴포넌트
- 소프트웨어 아키텍쳐
- The logical organization of distributed systems
- 통짜 소프트웨어 vs 컴포넌트?
- 컴포넌트쪽이 replacable하다.
- Connector
- 컴포넌트간의 관계.
- 분산시스템에서 프로세스가 컴포넌트
- 프로세스간 데이터 교환수단.
- low-level: TCP/UDP
- RPC, message passing or streaming data
- Styles
- Layered architectures
- Object-based architectures
- Data-centered architectures
- Event-based architectures
- Distribution transparency
- distribution transparency를 고려해야한다.
- 성능과의 trade-off
- 프로그래밍은 쉬워지는데 성능은 구려진다.
Layeded architectures
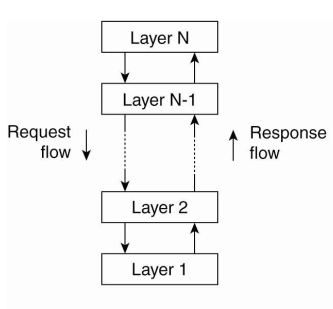
- 컴포넌트는 layered
- N 레이어 컴포넌트는 N-1레이어 컴포너트 호출로.
- 다른 방법은 x
- 네트워킹 커뮤니티에서 널리 채택되고 있다.
- OSI 7layer…
- 비효율적일지도. (performance 측면에서)
Object-based architectures

- 좀더 loose. 제약이 없다.
- (remote) procedure call
- client-server 시스템 아키텍쳐.
Data-centered architecture
(app 1) write -> (db) -> read (app 2)
- 중앙에 데이터 repository가 존재
- 컴포넌트간 데이터를 주고받을 repository
- 컴포넌트는 repository 한테서 데이터를 받아간다.
- Web기반 분산시스템이 data-centric
- 직접 전달하면 되지 않나?
- 언제, 어디서 사용할지 모르니까, 언제, 어디서든 접근할 수 있게
Event-based architectures
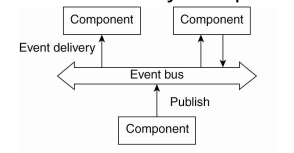
- 데이터를 전달하려는 컴포넌트 “메세지를 지금 보낼테니 지금 당장 필요한 컴포넌트가 써라”
- 미들웨어 - 이벤트 버스
- “어떤 데이터를 받고자 하는지”
- 누구에게 전달? pub/sub 시스템
- 모든 component사이의 “관심사가 등록되어 있다.
- IoT에서 sensor data -> 뿌려준다.
- 통신 프로토콜 MQTT
- “관심사"에서 업데이트가 있을 때 바로 받을 수 있다.
- Data-centered와 비교
- Data-centered는 두 component가 모두 online일 필요가 없다.
- Event bus에서 저장하면 된다.
- pure event-based에선 전달의 역할. 저장x
- 저장해봐야 소용이 없는, 그 순간에 필요한 데이터
- “그 순간의 온도정보”, 누가 쓸지 모르는
- Event-based + data-centered architecture
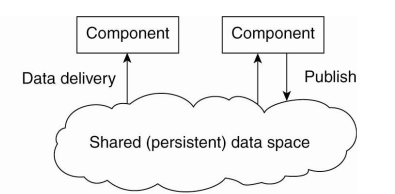
- subscribe는 해뒀는데 당장 online이 아니다.
- repository에 저장해놓자.
- subscribe는 해뒀는데 당장 online이 아니다.
분산시스템이 노리적/물리적으로 어디에 위치해 있어야 하는가, 역할은?
- Centralized architectures
- server-client
- Decentralized architectures
- 클라/서버 역할 구분이 없다.
- Hybrid architectures
- 유의.
- centralized - data-centered
- decentralized - event-based
- 다른 관점이다.
Centralized architectures
- client-server 모델.
- request-reply의 반복
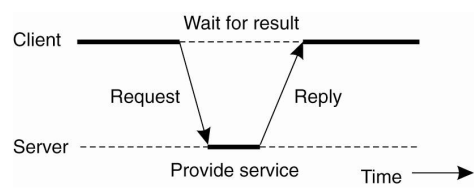
- request-reply의 반복
- 서버와 클라이언트 통신. (모든 서비스가 서버에 집중되어 있다.)
- TCP? UDP?
- Connection protocol (ex. UDP)
- 빨리 보낼 수 있다. 보내고 끝. 유실 가능성
- 메세지가 없어질 수 있다. 고려 필요.
- transmission failure 탐지. 재전송
- Client -> Server
- wait reply. 그런데 reply가 안온다면?
- request 유실? reply 유실?
- reply유실의 경우
- 서버는 request를 잘 처리했다. request가 다시 와도 되겠는가.
- “내 은행 계좌에서 1000$ wjsthd”
- server에서 state를 바꾸는 request
- not idempotent
- “내 돈이 얼마나 남았나”
- state 조회. 반복되서 실행되도 문제 없다.
- idempotent
- 같은 subnet 환경이라면 UDP여도 큰 문제가 없다.
- Connection-oridented protocols (TCP)
- 90% 이상 TCP
- TCP가 알아서 메세지 전달 잘 해준다.
- 사전작업이 필요하다. connection
- 오래걸리는 이유
- 90% 이상 TCP
Centralized architectures: application layering
- 메인 이슈
- 어떤 컴포넌트가, 서버에 적합할지 클라에 적합할지.
- 클라에서 돌릴까 서버에서 돌릴까
- 역할을 분명히 해야하지만.
- ex) 서버가 여러개?
- 계층적으로 1서버가 다른 서버의 클라가 될 수도 있다.
- 크게 3가지로 나누어 지더라.
- The user-interface level
- The processing level
- The data level
- 어떤 컴포넌트가, 서버에 적합할지 클라에 적합할지.
- The user-interface level
- 어떻게 상호작용 할 것인가.
- user “input” 수단. 처리결과 “output” 역할
- Display management
- 클라이언트단 구현
- 가장 단순하고 중요하다.
- Text만 뿌려주는 것만으로도 UI가 되기도.
- Text기반, GUI기반…
- 사요자에게 보여주려는 데이터는 UI레벨에서 가공할 수 있다.
- UI 역할도 독립적으로 UI만이 아닌 processing과 상호작용으로내부적인 processing이 있을 수 있다.
- The processing level
- 아마 가장 중요할 듯. 데이터를 찾아주고 계산해주고.
- 공통된 기능이 별로 없다. (UI는 공통된게 많을 듯.애플리케이션에 관계 없이)
- ex) Internet search engine. 중앙집중 분산시스템
- UI: text
- processing: 페이지를 찾자. ranking 알고리즘
- data: web pages.

- ex) a decision support system for stack brokerage
- 주가 데이터 분석/예측
- ex) desktop package
- 워드프로세서, 액셀, 파워포인트
- The data level
- persistent 데이터
- 애플리케이션이 계산할 데이터
- 서버측에 두는 게 일반적 (중앙집중형)
- consistency transparency
- consistency가 깨질 수 있다. read, write conflict
- 복제된 데이터 sync
- 애플리케이션 특성에 따라 달라진다.
- rdb 많이 썼다.
Centralized architectures: Multi-tiered architectures
- Three logical levels supports
- UI
- processing
- data
- 단순한 구현
- client -> UI
- server -> processing, data
- 이렇게 단순하지 않을 수 있다. 많은 구분이 있을 수 있다.
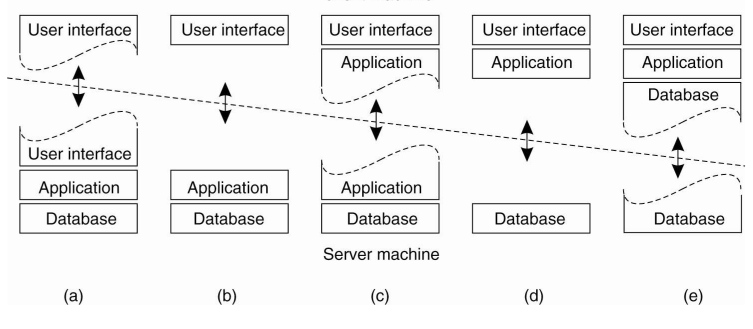
- (a)
- client: 사용자가 주는 input을 서버로 전달할 뿐. lightweight
- server: 사용자가 요청한 서비스를 client에게 보내기 전에 visualization을 server에서 조금 하자
- (b)
- client는 processing을 하지 않는다.
- client에서도 processing하는 게 좋다. 오늘날 일반적이지 않다.
- client는 processing을 하지 않는다.
- (c)
- overall communication latency를 줄이기 위해 클라이언트에서 processing을 하자
- ex) word proessor
- basic editing
- 스펠링 체크, 문법 -> 서버, 도움말
- (d), (e)
- UI와 processing을 모두 client에서. server는 데이터만.
- client가 무겁다.
- 인기 있는 구성인가? 아닌듯.
- ex) banking application
- ATM
- e) ex) web 클라이언트 캐시
- Multi-tiered architectures

- application server가 database server 입장에서는 클라이언트
Decentralized architectures
- Vertical distributions -> 중앙집중에서 고민하던 분산
- Horizontal distributions -> 모든 노드가 client/server
- peer-to-peer
- 왜?
- client-server
- peer-to-peer
- 일장일단이 있다.
- 서버가 없다. 동등한 역할의 노드들.
- 데이터는 어디에 두지?
- 내가 필요한 서비스를 누구에게서 찾지?
- client-server구조의 문제 SPoF.
- 서버의 부하가 크고 서버가 맛이가면 서비스가 죽는다.
- Scalability 이슈
- peer-to-peer
- peer 하나가 없어져도 서비스는 문제가 없다.
- 훤씬 확장성이 크다.
- 데이터를 누가?
- 서비스를 누가?
- peer들 끼리의 역할분담.
Decentralized architectures: Structured-P2P
- 모든 노드가 클라이자 서버다.
- 피어들간의 overlay network를 어떻게 구성할 것인가?
- overlay network: 논리적인 노드들, 프로세스들 사이에 연결이 맺어진 네트워크.
- 물리적인 연결은 다를 수 있다… 수많은 router
- 관리가 어렵다. 순수한 P2P는 없다. 중간에 서버등에서 데이터를 받아서…. 서버의 도움을 받는 경우가 많다.
- 어떻게 연결하지?
- blockchain
- peer들 끼리 다 연결? 일부만? -> 다양한 P2P 알고리즘
- Structured/Unstructured P2P
- 구조적 연결 rule - structured
- rule 없이 random - unstructured
- 다 연결하면 fully connected
- 연결이 너무 많아진다.
- 모든 connection을 맺진 말자.
- 필요한 peer들 기리 통신은 할 수 있는 연결을 만들자.
- 직접적인 connection이 됮 않는 경우도 발생
- ex) “Chord System”
- P2P application에서 P2P연결을 고민하고 싶지 않다.
- overlay network. chord가 알아서 해주겠다. 필요한 데이터.
- Structured P2P
rule을 만들때
distributed hash table (DHT)- key-hash-valueDHT-based system
- peer들 끼리: 누가 어떤 데이터를 담당할 것인가. (서버단에서 하던거)
- peer들 끼리: 데이터를 어떻게 나눌 것인가.
- 테이블을 쪼개서 나누자.
- key를 알면 key를 관리하는 peer를 알 수 있다.
- peer들 끼리 데이터를 쪼개서 관리한다
- DHT
- 필요한 노드들에게 키를 할당
- 무작정 random은 아니고, key를 할당.
- hash function
- A -> (hash) -> key
- 모든 peer가 같은 hash function을 쓴다.
- 모든 peer는 같은 key에서 같은 data를 얻는다.
- peer들도 id를 hash해서, key값이 존재
- 데이터 lookup하려면
- local에서 key를 구하고
- p2p에서 이 key를 관리하는 peer를 찾고 “A는 이 peer에서 관리하고 있어”
ex) the Chord System
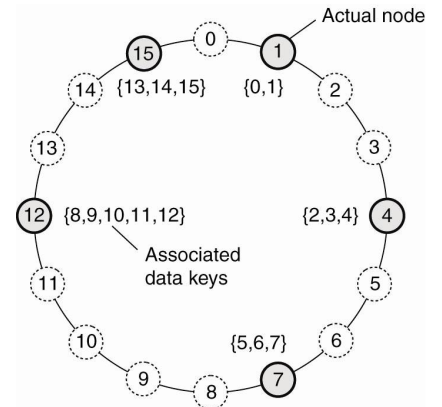
- 노드들 사이 overlay network는 ring형태
- 노드는 양쪽 노드와 연결 (2개 노드)
- successor, predecessor
- 새로운 노드는 어떻게 참여하지?
- 노드 id, 데이터 key
- K를 관리할 노드는 K보다 크거나 같은 노드 id중 가장 작은 노드 의 노드
- Lookup(k)
- succ(k)가 뭔지 찾아보자.
- Membership management
- peer가 들어올 수도 있고 나올 수 있다.
- 그때그때 상황이 바뀐다. 어떻게 관리할 것인가?
불편하지만 장단점이 있다.
- client/server의 문제점: server가 죽으면 어떡할 것인지? 서버가 강해야한다.
- p2p: peer가 죽어도 전체가 마비되지 않는다. 확장성을 이루기 좋다.
Decentralized architectures: Unstructured-P2P
- 주먹구구식으로 P2P 구성 randomized algorithm
- 어떤 peer와 연결? 어떤 데이터를 관리? -> random
- 각각의 노드는 neighbor의 리스트를 관리. 이웃 노드들
- overlay rule이 없다. 임의의 peer끼리 연결. 개수도 모르고
- 데이터를 어떻게 찾지?
- lookup을 어떻게?
- To flood the network: 전 네트워크에 모두 물어본다.
- broadcast -> 네트워크가 혼잡해진다.
- WAN에서는 router레벨에서 broadcast가 막혀있다.
- lookup을 어떻게?
- 멤버쉽 관리?
- 각자가 갖고있는 neighbor 정보를 업데이트 - 노드가 뭐가 있는지 알 수 있다.
- 새 노드가 참여하기 위해서? broadcast. 노드탐색, 정기적 갱신.
- 장점은?
- partial view: neighbor 정보 교환, 업데이트
- 문제점을 보완하기 위한 시도들 (다중 서버 구조, P2P)
- Super peer -> 서버를 두겠다. 완전한 서버는 아니고, P2P가 섞여있다.
- 다른 peer보다 더 강력한 정보, 강력한 power
- superpeer가 없을때 peer를 찾기 위해 broadcast, flooding 해야한다.
- 물어볼 상대를 두자. superpeer (special node)
- 어떻게 찾지? 합의… 정하는 알고리즘. distributed
- 데이터를 찾기 위해 일단 superpeer에게 물어보자
Decentralized architectures: Hybrid architectures
- Centralized (client-server) + Decentralized (P2P)
- 장점만 뽑아쓰자.
- 필요할 때 서버에 물어보고,
- 피어끼리 정보교환하고
- BitTorrent
- “tit-for-tat”
- 배반하지 않는 한 최대한 협조.
- 파일을 주고 받는건 P2P
- 다운을 받으면서 upload, 서로서로 도우면서 하자.
- 파일을 많이 제공했으면 그만큼 빨리 받는다.
- 노드를 찾는건 client-server
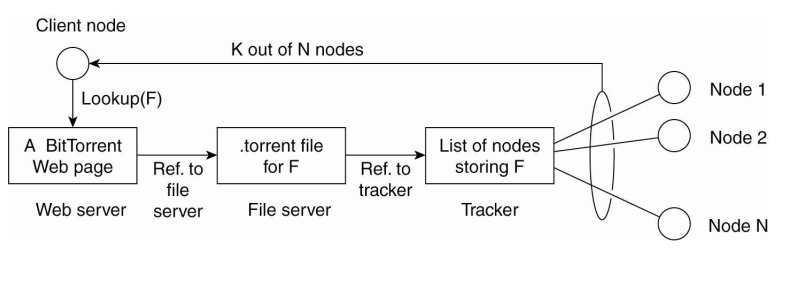
- “tit-for-tat”
Architectures vs Middleware
- Middleware
- overlay network찾기, 네트워크 통신 등 지저분한거 middleware가 다 해주겠다.
- (+)application 설계/개발이 simple해진다. 제공해주는 서비스 쓰자. Distribution Transparency
- (-)Middleware라는 추가 layer가 생긴다. performace가 떨어진다.
- ex) CORBA. object message broker
- app - (CORBA) - app
- 무겁다. 너무 많은 서비스. 느려지더라.
- 아키텍쳐가 고정적이었다.
- ex) CORBA. object message broker
- A better approach
- configure, adapt, customize가 쉬워야한다.
- 동적으로 behavior를 바꿀 수 있게.
- 애플리케이션에 맞게 policy 또는 mechanism을 변경
- policy는 쉬운데, mechanism을?
- Self-management
- 좋은 아키텍쳐: 적응형으로 mechanism을 바꿀 수 있다면
- automatic adaption
- 3가지 종류의 컴포너트가 필요하더라
- Monitoring -> 상황이 바뀌었음을 알아야한다.
- Analyzing the measumrements. Input/output 분석
- 서비스에 대한 상황이 문제는 없는지, 성능이 떨어짖니 않았는지
- Influencing the behavior
- 소프트웨어의 behavior를 상황에 맞게 바꿔라.
- Monitoring
- 클라이언트-서버 딜레이 체크
- Analyzing measurements
- 시스템 output을 정해진 값과 비교. threshold.
- 딜레이가 100ms보다 크지는 않은지.
- Influencing the behavior
- replica를 하나 더 두자
- Scheduling 우선 순위
- 서비스 switching
- Data migration
Chapter 3. Processes
- Virtualization
- 최근에 인기를 얻게 됐다.
Threads - concurrent
- The granularity of processes
- 다중 프로세스
- The granularity of threads
- 다중 스레드. 프로세스 하나에 동시에 돌아가는 효과.
- 물론 싱글코어라면 실제로 동시에 돌리는건 아니다.
- 사용자 입장에선 동시에 돌아가는 것으로 보인다.
- ex) 채팅프로그램
- 최소 2개의 프로세스.
- keyboard input thread,
- 받아서 화면에 뿌려주는 thread
- 최소 2개의 프로세스.
- 멀티프로세스 vs 멀티스레드 cost비교.
- 멀티스레드가 유리. context switch 오버헤드가 적기 떄문
- Introduction to threads (or process) 프로세스가 실행되려면, 스레드가 하나 있어야
- process, thread도 리소스 (소프트웨어 리소스)
- OS가 관리한다.
- program - 파일 상태, 실행이 되면 process
- 실행이 된 process는 OS가 관리
- 여러가지 정보 - PCB, CPU register, memory map, fd list
- 프로세스 -> 메모리 생성
- 아무데나 하는게 아닌, OS로부터 할당받는다.
- 프로세스 사이에 메모리 침법이 일어나지 않도록
- 실행이 된 process는 OS가 관리
- 다중 프로세스, 쓰레드를 통한 concurrency
- 사용자가 눈치채지 못한다 - transparancy
- OS가 알아서 complete independant address를 할당.
- 컨텍스트 스위치 비용이 프로세스가 상대적으로 비싸다
- CPU 1개 - 프로세스 변환 -> 다시 실행이 될 때
- 실행정보 save -> pc, stack, register -> load
- OS 레벨에서 컨텍스트 스위치에 필요한 데이터 수정
- 가상메모리면 memory translation cache 초기화
- 새로 실행할 프로세스 load, (thread가 더 가볍다)
- 이 비용이 thread에 비해 비싸다.
- 프로세스 스왑
- 메인메모리와 하드디스크 스왑
- “가상메모리” -> 필요한 정보 모두 load를 못했다.
- 물리적 메모리가 부족해서, 필요한 것만 load
- (퍼포먼스 개떡락)
- process, thread도 리소스 (소프트웨어 리소스)
- A thread
- 실행 흐름 프로세스 - 1 thread
- concurrent 동작을 위해 thread를 더 만들 수도 있다.
- thread 객체의 크기가 process에 비해 적다
- process-process 메모리 침범 보호 (OS가 보호)
- thread-thread 공유하는 메모리. 막 시도할 수 있다.
- OS는 침범을 막을 mechanism(lock)만 제공.
- 잘 짜야한다. application developer가.
- 다중 쓰레드?
- 다중 프로세스와 비교했을때 더 적은 cost
- 잘 짜야한다. 충돌을 OS가 막아주지 않는다.
- 싱글 쓰레드?
- 쓰레드를 쓰지 않는 그냥 작성한 프로그램
- blocking system call 반복.
- process performance가 떡락할 수 있다.
- 다 single thread로 만들 수는 있는데, 이상한 프로그램이 된다.
- ex) excel
- input 받아야 계산…
- input 받아야 하는데 계산…
- single thread면 input, 계산..
- cell이 바뀌면 다른 cell도 바뀌는데…
Threads: in distributed systems
- 분산시스템에서 스레드의 역할은?
- 컴퓨터 내 스레드가 아닌 여러 컴퓨터 내 프로세스와 쓰레드.
- 편하게 blocking system call 지원 (멀티 프로세스/스레드)
- 전체 process는 block시키지 않으면서.
- 분산시스템일때는 communication aspect이 들어간다.
- 다중 스레드로 분산시스템 성능이 향상될 수 있다.
- I/O 등.
- multithread - client
- 클라이언트 multithread -> communication delay down
- To hide the delay. 숨길수도 있다.
- ex) web browser
- 연결을 맺고, web document 요청/응답
- web document: text, image, video, contents, 사이즈가 크니 delay가 클 수 있다.
- 실제로 연결해보면 text는 금방보고, images는 나중에
- 출력하는 thread, contents receive thread 별도로
- 사용자는 text를 오래 기다리지 않아도 된다.
- connection을 1개만 두지 말고, 여러개 만들어서 사용자가 요청한 컨텐츠를 parallel하게 받자.
- ex) web browser
- multithread -server
- 멀티쓰레드의 효과는 서버가 더 크다.
- 서버는 거의 필수로 써야한다. high-performance를 위해서.
- 언제나 high performance? 사용자가 많이 몰렸을때.
- ex) file server
- file open, read, update, request
- 실제 operation은 전부 server에서.
- file I/O 작업을 해야한다. blocking.
- 싱글쓰레드로 할 수는 있겠는데, blocking.
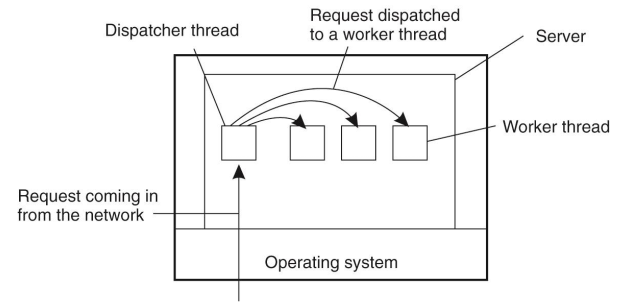
- Dispatcher.
- 클라이언트에게 request를 받아서 worker에게 task를 넘겨준다.
- Worker.
- Dispatcher에게 task를 받는다.
- read / write / update
- blocking system call을 알아서 잘해라.
- Worker하나가 blocking 된다고 프로세스가 멈추지 않는다.
- Dispatcher가 다른 worker에게 주면 되니까.
- Dispatcher.
- 다중쓰레드가 아니면
- main loop이 하나, request 하나 받아서 처리, I/O 대기, 알려주고, 반복
- DISK I/O 하나가 오래 걸리는 거면, 프로세스 하나가 멈춘다.
- blocking system call을 쓰지 않으면 성능이 향상될 수 있다.
- non-blocking system call을 이요
- thread가 하나임에도 다른 thread와 유사하게 가능
- blocking -> I/O를 기다린다.
- non-blocking -. 바로 return이 된다.
- 읽을 수 있는지 없는지 try.
- 읽을 수 있으면 읽고 return, 없으면 그냥 return
- asyncronous system call일 수도.
- async는 요청해놓고 바로 return을 받아서 다른 걸 한다.
- 읽어줘. 나는 다른걸 할게.
- async는 요청해놓고 바로 return을 받아서 다른 걸 한다.
- non-blcoking은 계속 tracking해야한다.
- 나중에 check - state 유지
- 먼저 request 받는다.
- task 수행을 해야한다면 I/O -> I/O 시스템콜 수행, async, non-blocking
- 다음 클라이언트 (I/O는 처리중)
- non-blocking 시스템콜이면 이번에 안됨 -> 다음에 다시처리 (반복)
- thread는 blocking 되지 않는다.
- 쓰레드가 너무 많은 것도 오버헤드.
- Threads
- parallelism, blocking
- Single-threaded process
- No parallelism, blocking
- Finite stete machine
- Parallelism, nonblocking
- Threads
- 개발하려는 서버의 특성에 맞게.
Virtualization
- illusion
- CPU는 1개인데 동시에 실행되는 듯한 환상.
- 자원을 가상화.
- 가상화의 역할 (윈도우 쓰고 있는데 리눅스가 쓰고 싶어)
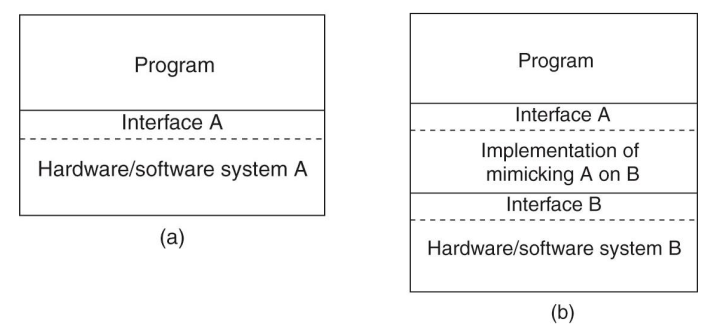
- A를 B에서 어떻게 돌리지?
- porting…
- layer를 두자! -> 가상화. 다른 시스템을 흉내낸다.
- 느려진다는 문제점.
- A를 B에서 어떻게 돌리지?
- Architectures of virtual machines
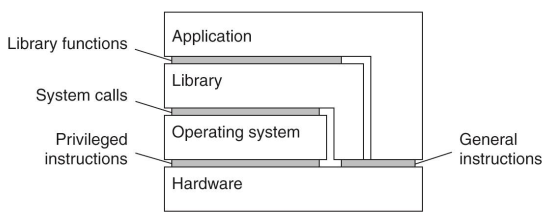
- 가상화.
- 인터페이스의 behavior를 흉내내겠다.
- Two ways of virtualization
- A process virtual machine
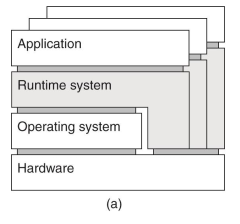
- 다른 플랫폼에서 돌아가는 application에 필요한 abstract instruction을 제공한다.
- JVM
- emulation 하는 개념?
- A virtual machine monitor (VMM)
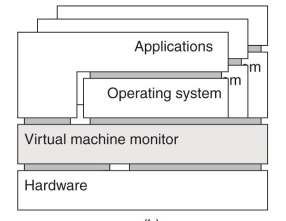
- Hardware 전체를 제어할 수 있는 interface, OS 여러개 설치 가능
- Application이 직접 Hardware에 access가 가능. 이쪽이 더 성능이 좋다.
- VMM 기술이 좀 더 중요해 질 수 있다. 확장 가능성.
- 대신 어렵다. 잘 되면 reliability, security up.
- ex) windows 시스템을 VMM 위에서 돌리고 있었다.
- 그리고 해킹을 당했다. 바이러스
- 전체 시스템에 영향을 주는건 아니고, window만.
- 다른 linux들은 영향 최소화.
- portability
- hardware와 software의 중간 layer
- hardware 교체하기 훨씬 편하다. maintance up
- A process virtual machine
- 가상화.
Clients: Network user interfaces
- Client machine의 major task.
- UI 제공. 사용자대신 서버에 요청, 요청수단.
- 2가지 방법
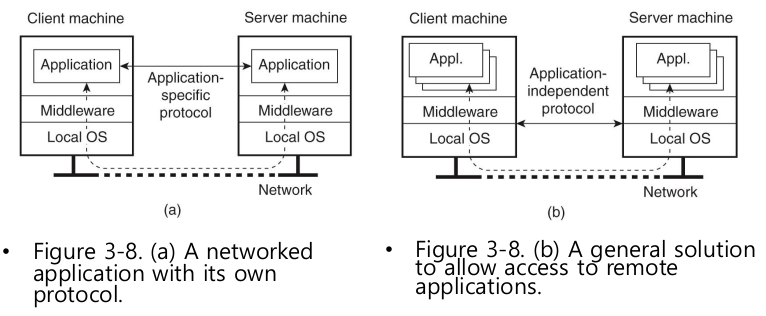
- (a) application-specific
- client가 하는 일이 더 많다.
- ex) 일정관리 프로그램. 전용 프로토콜
- application이 꼭 필요한 경우 (b)는 제공하기 어렵다
- (b) application-independant
- Middleware가 제공하는 common한 서비스만 이용하겠다.
- ex) terminal을 통해서 middleware가 제공하는 것만 하자.
- Client가 하는게 거의 없다.
- UI만 하겠다.
- processing은 모두 서버에서.
- (a) application-specific
Clients: Client-side software
- 단순히 UI만 제공하는 건 아니고, UI 이상의 task, role
- 자체적인 데이터 관리, processing
- ATM, 셋탑박스.
Clients: transparency
- Distribution transparancy
- 클라이언트도 이를 제공하면 좋다.
- 사용자가 프로그램을 이용하는데, 서버와 연결한다는 것 자체를 모른다.
- Local 프로그램을 사용하는 것 처럼, 이상적인 환경
- Server단에선 performance 측면을 봤을 때 distribution transparency를 client보다는 덜 제공하자.
- 상황에 맞게, 적당히
- 클라이언트도 이를 제공하면 좋다.
- Access transparancy. 동일한 방법으로 연결
- client stub을 이요해서 middleware의 서비스를 이용
- 액세스 방법이 다른 esource가 있다고 해도 client stub이 이를 제공
- same interface
- access transparancy 제공
- client stub을 이요해서 middleware의 서비스를 이용
- Location, migration, relocation transparancy
- middleware가 숨긴다.
- 사용자는 모른채로
- replication transparency도 middleware가 숨긴다.
- replicated servers
- replicated requests
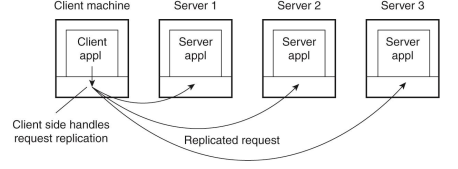
- middleware가 숨긴다.
- Failure transparancy
- 클라이언트 미들웨어를 통해 서버와의 communication failure를 숨긴다.
- ex) 반복적 재연결 시도.
- 여러번 실패하면 다른 서버로
- ex) 연결은 실패했지만, 캐시된 데이터를 제공
Servers: General design issues
- 클라이언트는 사용자 편의성
- 서버는 클라이언트에게 서비스를 편하게 빨리
- performance가 주된 이슈
- Interative server?
- process가 하나
- thread가 하나
- Concurrent Server
- 다중 쓰레드
- Interative보다 성능이 좋다.
- 멀티 프로세스가 대안
- UNIX. -> 요청에 따라 fork
- 어떻게 편하게 클라이언트에게 서비스를 제공할 것인가?
- performance보다는 client 편의성 측면
- 표준 port -> FTP(21), HTTP(80) well-known port
- 표준이 아닌 port 번호라면?
- 섭에 물어보는 절차가 필요할 수 있다.
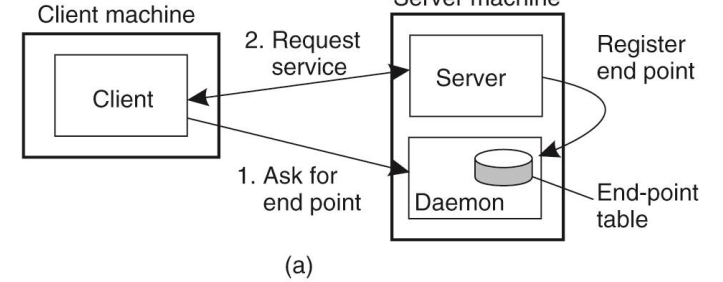
- 섭에 물어보는 절차가 필요할 수 있다.
- 리소스의 낭비는?
- 클라이언트가 없는게 계속 돌고 있어야한다.
- 이 리소스 낭비를 해결 항 방법
- 프로세스를 평소엔 돌리지 않다가, 요청하면 프로세스를 돌려라.
- UNIX inetd daemon
- 필요할 때만 프로세스가 생성이 되서 서비스를 제공한다.
- 중간에 client가 사정이 생겨서 요청한 서비스를 중단 시킬 수 있을까? (Interrupt)
- 메신저 - 메세지 취소, 메일
- Simple solution: 클라이언트 강제 종료 -server는 client가 강제종료 됐구나. 하고 연결을 끊을 것.
- better approach: out-of-band data
- non-out-of-band: 클라이언트가 정상적으로 주고받을 때 쓰는 데이터
- out-of-band: 그 이외. 긴급 메세지를 사용해 취소.
- 긴급 connectionㅔ서 out-of-band
- 리소스 낭비. 원래 쓰던 connection에선 못하나?
- TCP header -> out-of-band
- TCP header를 안쓰면?
- 그냥 보내면 순서가 밀린다.
- non-blocking system call이면 가능하겠다.
- Stateful / stateless 서버
- stateful: 클라이언트 상태를 저장하는 서버
- stateless: 그냥 request 오면 처리하는 서버
- stateless 서버
- 장점: 현재 연결된 클라이언트와 아무런 연관 정보가 없다.
- 서버의 상태변경이 클라이언트에 영향을 미치지 않는다.
- stateful은 클라이언트에 영향을 끼치게 된다. 관리가 복잡해진다.
- ex) web server
- 웹브라우저의 상태정보를 저장하지 않는다. (원래는)
- 웹메일, 쇼핑몰, … 백엔드에서 클라이언트 정보를 저장할 수도. 쿠키
- 실제로는 client information을 유지하는 경우가 대부분이다.
- ex) 클라이언트 request logs
- 날라가도 전체서비스에 큰 영향은 없는 정도.
- 장점: 현재 연결된 클라이언트와 아무런 연관 정보가 없다.
- Stateless와 Stateful의 중간단계. soft state
- 저장을 하긴 하겠다. limited time 동안.
- 서버가 state를 바꾸면 client에 이를 통지한다. (push)
- limited time이 지나면 통지하지 않는다.
- Stateful
- 클라이언트에 대한 정보를 활용해서 서비스를 좀 더 효율적으로
- performance 측면에서
- ex) file server maintain a table containing (client, file) entries
- 클라이언트가 파일에 액세스하는 순간 다 기록하겠지.
- 어떤 클라이언트가 어떤 파일에 access 하는지.
- (+) 클라이언트가 이 서버에 있는 파일에 대해서 read/write operation performance 향상. -> 클라이언트가 1파일에 대해 계속 요청. state 유지. file을 open한 채로 둔다.
- (-) 서버가 크래쉬가 나면 테이블의 정보가 날라가고, 복구가 까다로워진다.
- 똑같은 file server를 statelss로 구현하려면.
- loop를 돌면서 write…
- file open-write-close 매번 찾아서.
- 서버가 느려지는 가장 주된 원인은 I/O -> network I/O, file I/O.
- 클라이언트에 대한 정보를 활용해서 서비스를 좀 더 효율적으로
- 서버를 구현한다고 하면 보통 stateful.
- 어떤식의 서비스건 동일하게 수행할 수 있어야 한다.
- 퍼포먼스 / 클라이언트 편의성
- ex) 다시 그 파일서버
- stateful: open file 정보를 유지
- stateless: read/write request 가 온다면
- 매번 파일을 열어서 read/write, 그리고 close
- 메세지 크기도 커질 수 있다.
- ex) 클라이언트의 과거 상태 정보도 안다면, 더 퀄리티 향상이 가능
- 쇼핑몰, 과거 구매이력을 ㅗ추천
- stateless라면 클라이언트가 추가정보를 전송해야한다.
- cookie
Server cluster: 다중 서버.
- 어떻게 구성하지?
- 서버머신이 많아졌을 때 한 곳에 모아놓고 고속망으로 연결.
- 물리적으로 server들을 local LAN으로 연결.
- 3가지 역할, 3tier
- First tier
- Second tier
- Third tier
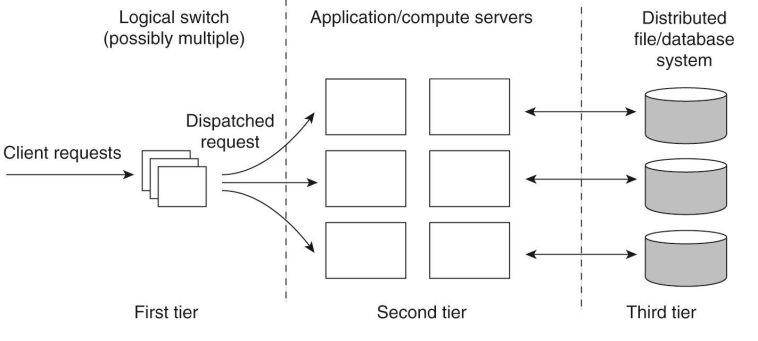
- server cluster가 여러 서비스르 ㄹ제공할 때
- 다른 머신에서 다른 application이 돌아가는 상황
- switch가 복잡해진다. 서비스 종류를 구분할 수 있어야 한다.
- Access Transparancy 고려. 사용 편의성을 위해
- client는 동일한 방법으로 request를 날려서 reply를 받을 수 있어야 한다.
- server는 client에게 1개의 access point를 제공
- A 서비스 a port, B 서비스 b port면 access transparancy가 꺠진다.
- scalability, availability를 위해선 여러 access point를 제공하는 것이 좋다.
- 사용가능한 access point는 여러개, client에겐 변경되지 않는 1개의 access point 제공
- 서버쪽에서 access point가 바뀌어도 clinet에게 알려주지 않도록.
- 어떻게?
- TCP
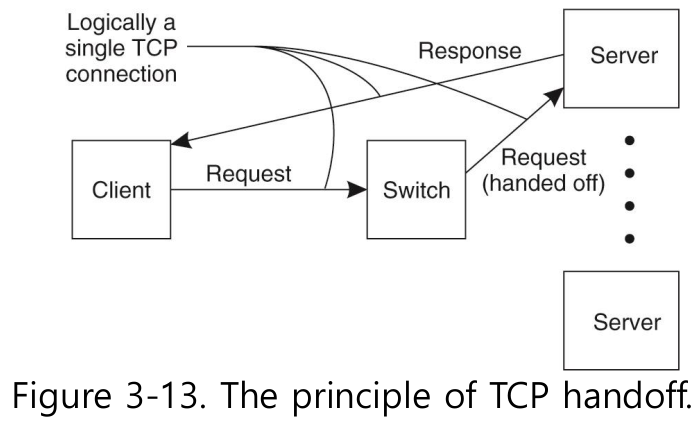
- Transport-layer switch에서 TCP 연결 요청을 받아서, 다른 서버의 연결로 넘겨준다.
- client에게는 1개의 access point, 실제 processing은 다른 노드 일 수도
- 실제 서버가 client로 reply를 날려줄 때 보내는 놈의 주소를 자신이 아닌 switch의 주소로 넣는다.
- client는 “switch가 보내줬구나"라고 판단.
- TCP hand off는 OS레벨 support가 필요. 그냥 application에선 어렵다.
- 왜 하지 이짓을?
- client에게 single access point 제공
- TCP
- Load distribution among servers
- 놀고 있는 서버를 잘 찾아서 request 배분
- Simple solution: Round robin
- Advanced server selection: 서버 상태 monitoring 스위치
- One step further
- request packet을 뜯어서
- request의 종류 뿐만 아니라 client에 대한 정보도 확인, 적절한 서버에 넘겨준다
- content-aware request distribution
- 놀고 있는 서버를 잘 찾아서 request 배분
- distributedservers:
- single access point의 문제
- point가 fail나면 클러스터 전체가 unvailable이 된다.
- solution
- 여러 backup access point
- DNS 호스트 name은 1개, 여러 ip를 mapping할 수 있다.
- 이걸 클라이언트에 그대로 적용하면
- 아, access point가 여러개네
- 물론 client middleware가 application 모르게 할 수 있다.
- 클라이언트에게 1개의 static access point를 제공하고자 하는 청학엔 맡지 않다.
- statble하고 static한 1개의 access point… desirable feature
- Flexible server cluster
- access point 역할을 하는 놈이 죽으면 다른놈이 하도록 하자. -> distributed server
- 서버가 dynamic하게 바뀔 수 있다. access point도 바뀔 수 있다.
- client는 동일한 방법으로 접근 할 수 있다.
- 여러 backup access point
- server cluster에서 구성이 좀더 flexible해졌다.
- client가 stable한 server의 service를 이용할 수 있나.
- server는 cluster 형태. 그때그때 역할을 대신할 수 있다. client에게는 이를 숨긴다.
- 어떻게 하지?
- MIPv6. Mobile IPv6. 지역이 바뀌어도 IP는 그대로.
- home network에서 home address 할당받은 디바이스.
- speical router
- 외부에서 오는 트래픽은 모두 home agent를 거친다.
- 문제는 Mobile device가 이동할 수 있다. -> home address는 더이상 쓸 수 없다.
- 임시로 새로 받는 주소 care-of-address. 이를 자신의 home agent에게 알려준다.
- hom agent가 forward를 해준다. mobile device는 계속해서 트래픽을 받을 수 있다. 어디에 있든 상관 없이.
- stable access point
- “A"라는 contact address.
- 노드 1개가 contact address를 사용하여 access point 역할
- 이 ccess point 노드는 자신의 주소를 agent에게 등록한다.
- 모든 트래픽은 B로 간다. B가 분배
- B가 죽으면 다른 노드가 다시 등록을 한다.
- Bottleneck 문제
- Home agent, access point가 트래픽을 다 받는다.
- Solution: 모든 트래픽이 agent를 거치지 않게끔 하자.
- Solution: route optimization feature
- MIPv6
- home agent가 care-of address를 클라이언트에게 알려주자.
- client가 (HA, CA) pair를 갖는다
- home agent의 부담이 줄어든다
- 이상하다. 클라이언트가 이걸 모르게 하려고 했는데.
- 이 pair는 client application이 아닌 client middleware에서 유지한다.
- middleware가 HA를 CA로 바꿔서 보낸다.
- Application은 계속 HA를 쓰고, MIPv6가 HA를 CA로 바꿔서 쓴다.
- Distributed system
- access point를 여러개 만들자.
- Home agent에 트래픽이 몰리는건 어쩔 수 없다.
- 트래픽이 한곳에 몰리는 케이스는 막을 수 있다.
- MIPv6
- single access point의 문제
