
Operating System
건국대학교 운영체제 강의노트
http://pages.cs.wisc.edu/~remzi/OSTEP/#book-chapters
CPU virtualization
Process
(1)
- Program vs Process
- Program
- Executable 파일
- instructios, static data
- Process
- 실행되고 있는 프로그램
- Machine stae
- Memory: instruction and data
- Register: PC, stack pointer, …
- Others: 프로세스가 open한 파일 리스트. (우리가 file을 close하지 않아도, 프로세스가 종료할 때 운영체제가 알아서 close 해준다.)
- Program
- API
- create, destory, wait, miscellaneous control
- fork()
- parent, child
- 실행되는 순서가 다를 수 있다: OS process schedulling policy
- 따라서 순서를 예측할 수 없다.
- wait()
- child가 하나라도 종료되는 걸 기다림.
- waitpid()
- 특정 child 프로세스가 종료되는 걸 기다림.
- exec()
- 기존에 있던 프로세스를 덮어쓴다.
- 일반적으로 fork()하고 child에서 exec
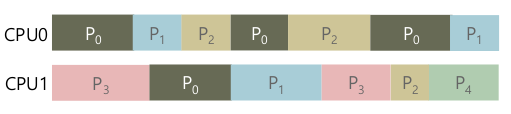
- 프로세스가 여러개 -> 컨텍스트 스위칭
- 동시자원 접근
- timer, I/O request등 인터럽트가 일어나면 컨텍스트 스위칭 (그리고 OS에서 어떤 작업을 수행한다.)
- 코어는 한정적. 많은 프로세스를 어떻게 효율적으로 처리할 것인가?
- Ideal: 동시에 처리
- Reality: 프로세스가 CPU 선점, 자원 독차지
- 운영체제는 application 개발자에게 어떻게 Ideal하게 제공할 수 있을지 고민한다.
- Time sharing
- 많은 가상 CPU가 존재한다고 생각. (실제 CPU는 몇몇개 정도로 한정적)
- 원하는 만큼 동시에 (councurrent) 프로세스 실행
- 비용
- CPU가 공유된다.
- 이는 효율적인가? (Context switching overhead)
- 컨텍스트 스위치
(2)
- Process State
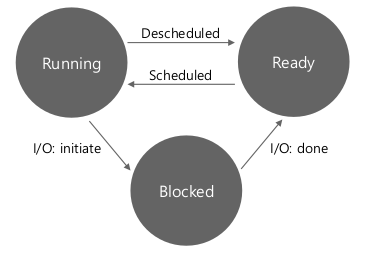
- Running: 프로세서에서 돌고 있다.
- Ready: 준비되어 있다. CPU가 아직 안꺼내갔다.
- Blocked (Waiting): not ready.
- Disk I/O, Network I/O 는 CPU보다 굉장히 느리다.
- 여기서 데이터가 올때까지 기다린다 -> Process Block
- example
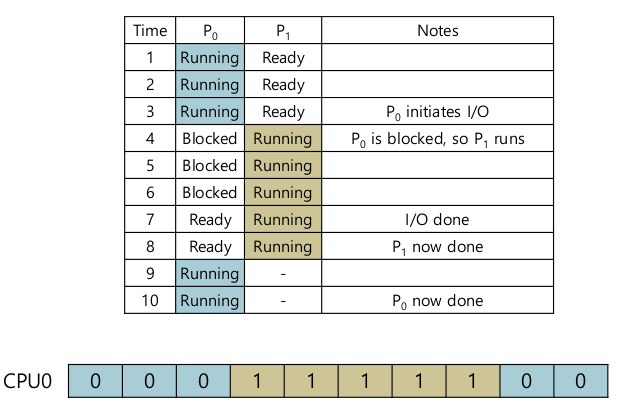
- data strutures:
/include/linux/sched.h
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
/* -1 unrunnable, 0 runnable, >0 stopped: */
volatile long state;
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
void *stack;
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* Current CPU: */
unsigned int cpu;
#endif
struct mm_struct *mm;
struct mm_struct *active_mm;
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
}
- Scheduling queue
- Run queue
- Ready queue
- Waiting queue
- 운영체제 입장에서 어떤 process가 어떤 state에 있는지 빨리 찾아야할 필요가 있다.
- ex) 한 프로세스가 너무 길게 run -> (run <–> Ready)
Limited Direct Execution
프로세스에게 CPU 자원을 주고, “하고 싶은 대로 다 해봐라”
| OS | Program |
|---|---|
| Create entry for process list | |
| Allocate memory for program | |
| Load program into memory | |
| Set up stack with argc/argv | |
| Clear registers | |
| Execute call main() | |
| Run main() | |
| Execute return from main() | |
| Free memory of process | |
| Remove from process list |
프로그램이 돌아가는 중에 OS는 컨트롤 할 여지가 없다?
OS도 결국은 실행코드 집합. CPU 자원이 있어야한다.
- 프로그램이 CPU를 갖고 있으므로
- 감시도 못하고
- Time sharing / Process policy / Context switch 하기 어렵다.
Problem 1: Restricted Operations (Previleged opeartions)
- How to perform restricted operations?
- Restricted operations (previleged operations)
- Issuing an I/O request to a disk
- Gaining access to more system resources
- CPU, memory 등 시스템 자원은 항상 모자란 자원. 유저 프로세스가 요청한 대로 다 제공 불가.
- 요청에 대해 얼만큼 허락할 것인지.
- Application은 제한된 operation을.
- 다만 프로세스에게 완전한 제어권은 X
- Restricted operations (previleged operations)
- Processor modes: CPU가 제공하는 기능. Intel은 4가지 모드 제공, 운영체제는 User, Kernel 쓴다.
- User mode: Restricted operation 사용 불가.
- 유저 모드 코드는 할 수 있는게 제한된다.
- 제한된 operation은 프로세서 exception을 일으킨다.
- Kernel model
- 코드가 뭐든지 할 수 있다.
- OS는 커널모드로 동작.
- User mode: Restricted operation 사용 불가.
- System call
- Restricted opeartion은 유저모드에선 불가. 하지만 필요하다 -> 시스템 콜.
- Trap instruction
- 커널 진입 (시스템 콜 호출시)
- previleged level을 kernel 모드로.
- previleged operation 수행
- Return-from-trap instruction
- 시스템 콜이 끝나고 호출되는 instruction
- 커널 모드 -> 유저 모드
- previleged level을 kernel 모드에서 다시 user mode로
- 유저 프로세스는 Retricted opeartion을 쓰기 위해 시스템 콜을 호출해야 한다.
- Trap -> (instruction) -> Return-from-trap
- Restricted Operation을 맘대로 못쓰게 하기 위해 프로세서 모드.
- 우리는 그냥 시스템 콜을 부르면 쉽게 커널 모드 진입. 허락되지 않은 일도 맘대로 할 수 있지 않을까.
- => 시스템 콜을 호출한 프로세스는 jump할 address를 지정할 수 없다.
- 정해져 있는 시스템 콜을 호출하게 되어 있다.
- 제공되는 Restricted operation이 대단히 제한적이다.
- Trap Table
- Trap instruction이 호출되었을 때 실행될 코드들, 즉 trap handler가 저장된 table
- 시스템 콜 number
- Trap instruction을 해도 특정 address 접근이 아니라, 미리 정해져 있는 number만 요청
- 운영체제가 미리 정의해 놓은 hadnler만 호출 => 운영체제 검사 => 통과, OS 코드 실행
- 여러 권한 검사
- 이 프로세스가 이 코드를 실행해도 되는가
- 이 trap number로 특정 호출을 해도 되는지.
| OS | Hardware | Program |
|---|---|---|
| Initialize trap table | ||
| Remember address of syscall handler | ||
| Create entry for process list | ||
| Allocate memory for program | ||
| Load program into memory | ||
| Set up user stack with argc/argv | ||
| Fill kernel stack with regs/PC | ||
| Return-from-trap | ||
| Restore regs from kernel stack | ||
| Move to user mode | ||
| Jump to main | ||
| Run main() | ||
| … | ||
| Call system call | ||
| Trap into OS | ||
| Save regs/PC to kernel stack | ||
| Move to kernel mode | ||
| Jump to trap handler | ||
| Handle trap | ||
| Return-from-trap | ||
| Restore regs from kernel stack | ||
| Move to user mode | ||
| Jump to PC after trap | ||
| Return from main() | ||
| Trap (via exit()) | ||
| Free memory of process | ||
| Remove from process list |
Problem 2: Switching Between Processes
- How to regain control of the CPU?
- CPU에서 프로세스가 돌고 있다면, OS는 돌고 있지 않다.
- OS가 돌고 있는게 아니라면, 이걸 어떻게 하지? (System call, Context Switching)
- Cooperative Approach: Wait for system calls
- 오래 실행되는 프로세스는 “주기적으로 CPU를 포기할 것"으로 추정
- 대부분의 프로세스는 CPU 제어권을 OS에게 꽤나 빈번히 넘긴다.
- 시스템 콜 내부에 스케쥴링 코드 => time sharing
- illegal operation 할 때도 제어권을 넘긴다
- Dividing by zero
- Segmentation fault
- 응용 프로그램에서 시스템콜을 부르지 않는다면?
- 운영체제 개발자는 Application 개발자를 믿지 않는다.
- 오래 실행되는 프로세스는 “주기적으로 CPU를 포기할 것"으로 추정
- Non-Cooperative Approach: The OS takes control
- Timer interrupt
- CPU에서 소프트웨어적으로 프로그래밍 가능한 timer를 제공.
- timer device는 주기적으로(1ms?) interrupt를 발생시킨다.
- 인터럽트 발생시 현재 프로세스는 머추고 사전에 설정된 인터럽트 핸들러가 동작한다.
- Timer interrupt
- Context Switch
- Saving and restoring context
- 몇몇 레지스터 값 저장
- 곧 실행될 프로세스 값 restore (kernel stack에서 꺼내서, kernel stack => 실행 프로세스)
- Return-from-trap instruction이 실해되면 system은 또 다른 프로세스 실행 재개.
- Saving and restoring context
(3)
| OS | Hardware | Program |
|---|---|---|
| Initialize trap table | ||
| Remember address of syscall handler | ||
| Remember address of timer handler | ||
| Start interrupt timer | ||
| Start timer(interrupt CPU in X ms ) | ||
| Process A | ||
| Timer interrupt | ||
| Save regs(A) to k-stack(A) | ||
| Move to kernel mode | ||
| Jump to trap handler | ||
| Handle the trap | ||
| Call switch() routine | ||
| save regs(A) to k-stack(A)* | ||
| restore regs(B) from k-stack(B)* | ||
| switch to k-stack(B) | ||
| Return-from-trap (into B) | ||
| Restore regs(B) from k-stack(B) | ||
| Move to user mode | ||
| Jump to B’s PC | ||
| Process B | ||
CPU Scheduling
(1)
- Workload Assumptions (Workload 가정)
- Each jobs (thread/process) runs for the same amount of time
- All job, arrive(실행할 수 있는 상태) at the smae time (ready queue 진입)
- 일단 시작하면, 각 job은 자원을 양보하지 않는다.
- 모든 job은 CPU만 사용. (I/O 가 없다. CPU를 양보하지 앟는다.)
- 각 job의 run-tim을 알고 있다.
- 다 비현실적 가정.. 이러한 가정에서 출발해서 조금씩 스케쥴링을 개선한다.
- Scheduling Metrics
$$ T_{turnaround} = T_{completion} - T_{arrival} $$
- 생선된 시간부터 종료된 시간까지 얼마나 걸렸는가.
- CPU 스케쥴링 평가 지표
- FIFO (First In, First Out): First come, First served (FCFS)

- 간단하고 쉽다.
- Average turnaround time: $$(10+20+30)/3 = 20$4
- 실행시간이 같다는 가정을 지워보자.

- Average turnaround time: $$(100+110+120)/3 = 110$$
- 오래걸리는 process가 앞에 있을 때 비횽ㄹ적.
- 전체 성능이 안좋아진다: Convoy effect
- SJF (Shortest Job First)

- 실행시간이 빠른 애들부터 먼저 하자.
- Average turnaround time: $$(10 + 20 + 120) / 3 = 50$$
- 모든 job이 동시에 올 때 최적
- 동시에 도착한다는 가정을 지워보자.
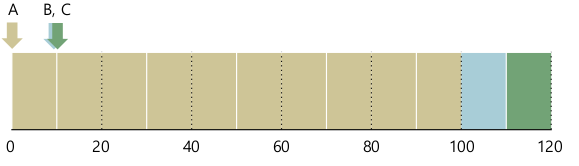
- Average turnaround time: $$(100 + (110 -10) + (120 - 10) / 3 = 103.33$$
- SJF에서도 Convoy effect 발생
(2)
Preemptive Scheduler
- Non-preemptive scheduler
- 일단 프로세스가 시작하면 다음 스케쥴링은 프로세스가 끝난 뒤 도착
- 현재보다는 과거에 했었던 방법. 계산 위주의 job.
- 한번 실행이 되면 runtime state를 모른다.
- 실행이 끝날 때 까지 wait => batched job
- Preemptive scheduler
- 어떤 프로세스가 선점하던 자원을 뺏어서 다른 프로세스에게 줄 수 있다.
- 실행하던 프로세스를 멈추고, CPU 자원을 다른 프로세스에게 줘서 다른 프로세스가 실행하도록 자원을 선점하게 하는 scheduler
- Context switch
- 현재 운영체제 대부분 preemptive scheduler
- Non-preemptive scheduler
STCF (Shortest Time-to-Completion First): Preemptive Shortest Job First (PSJF)
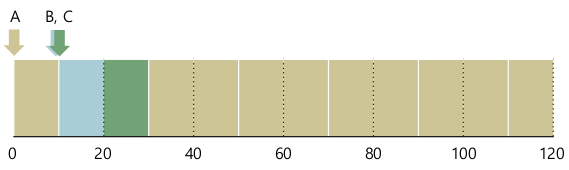
- Average turnaround time: $$ 120 + (20-10) + (30-10) / 3 = 50 $$
Scheduling Metrics
- Turnaround time
- Response time: job이 도착한 시점부터 running state까지 간 시간. $$ T_{response} = T_{firstrun} - T_{arrival} $$
- PSJF에서 average response time은 3.33
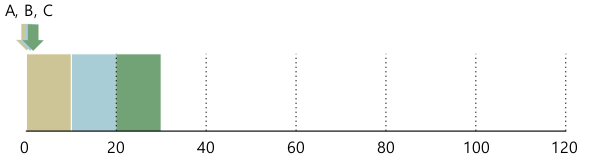
- turnaround time은 괜찮은데, response time과 interactivity가 별로다.
RR (Round-Robin)
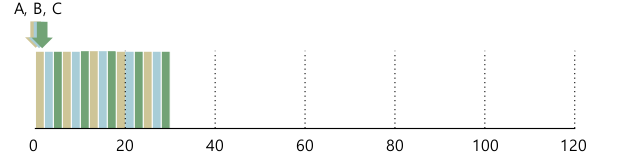
- = Time slicing
- 스케쥴링이 Time slice가 끝날때마다. (STCF는 프로세스가 새로 도착 / 혹은 종료될 때 뿐)
- Time slice: 2라 했을때
- Response time = $ (0 + 2 + 4) / 3 = 2$, turnaround time이 조금 구리다.
- 실행시간이 아무리 길어져도 response time은 동일.
- rseponse time vs turnaround time trade-off. slice가 짧으면 컨텍스트 스위치 overhead
- 어떤 종류의 application을 돌리지에 따라 다르다.
- 현재 스케쥴러는 모두 RR기반.
- 보통 사용자 device와 interactive 케이스가 많다. 일반적으로 RR이 성능이 좋다.
- 운영체제마다 time slice가 상수이기도, 동적으로 바꾸기도 한다.
프로세스가 CPU만 사용한다는 가정을 지워보자.
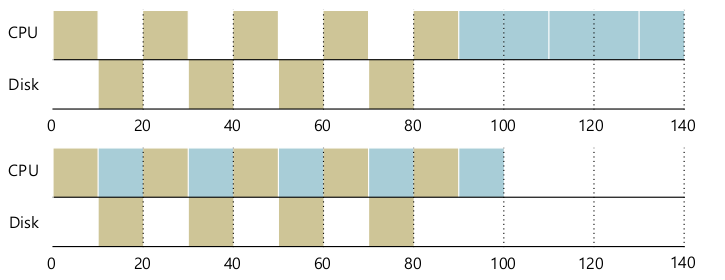
- 프로스세스가 blocked.
- 디스크는 CPU에 비해 굉장히 느리다.
- 인터럽트 - 시스템 콜.
- 놀 수 있는 CPU 자원을 다른 프로세스에게 양보.
마지막으로 실제 실행시간을 알고 있다는 가정을 지워보자.
- SJFT, STCF와 같은 접근은 불가능하다.
- 남는건 FIFO, RR
- 선택지는 RR밖에 남지 않는다.
- 현실적으로 타협가능한 알고리즘.
Multi-level Feedback Queue
(1)
- Crux of the Problem
- 아래 두개를 만족하는 스케쥴러는 어떻게 설계할까
- interactive job에 최소한의 response time
- turnaround time 최소화
- 실행시간을 우리는 모른다.
- 아래 두개를 만족하는 스케쥴러는 어떻게 설계할까
- Multi-level Feedback Queue (MLFQ): Multiple queues
- 각자 다른 priority level
- 한 순간에 한 job은 해당하는 한 priority level queue에 들어있다.
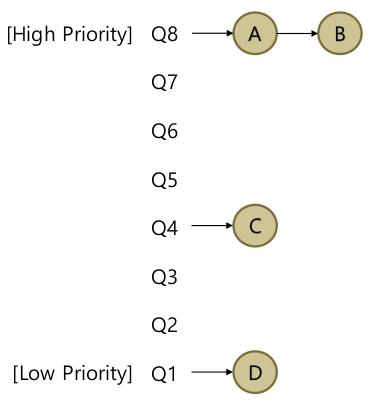
- Basic rules
- Rule 1: Priority(A) > Priority(B): A runs
- Rule 2: Priority(A) = Priority(B): A & B run in RR
- 위 그림에선 A, B가 다 끝나거나, I/O Blocked가 되야 C, D가 실행될 수 있겠다.
- 어떻게 priority를 주지?
- Fixed priority to each job (사용자 명시)
- 자기꺼가 가장 높은 우선순위 하겠지.
- 모든 프로세스가 가장 높은 우선순위 큐에만???
- OS는 application 개발자를 믿지 않는다.
- 동적으로 바꾼다 : 최근에 어떤 행동을 했는지 보고 이후 행동을 예측
- job이 CPU를 양보 (I/O blocked) -> 높은 우선순위, CPU를 오래 쓰지 않으니까.
- job이 CPU를 오랜시간 점유 => MLFQ는 우선순위를 내린다.
- Fixed priority to each job (사용자 명시)
- How to Change Priority
Workload
- I/O-bound jobs
- Interactive, and short-running: 사용자 입력, I/O data send/recv
- CPU-bound jobs
- 계산 집중적.
- I/O-bound jobs
Priority adjustment algorithm
- Rule3
- job이 시스템에 들어오면, 높은 priority
- Rule4
- a: time slice를 줄 때 마다 CPU를 소진하면. 낮은 priority
- b: time slice가 끝나기 전에 CPU 자원을 양보한다 => priority 유지
- Rule3
(2)
- Problems
- Starvation: I/O bound job이 많으면? Interactive job이 많으면?
- 모든 time slice를 I/O bound job이 갖는다. CPU bound job은 얻지 못한다.
- Gaming the scheduler: timer slice가 끝나기 전에 I/O 요청하면?
- Changing behavior: CPU bound -> I/O bound
- Starvation: I/O bound job이 많으면? Interactive job이 많으면?
- Priority Boost
- 주기적으로 시스템의 모든 job의 priority를 높은 쪽으로
- Rule5: S만큼 시간이 지난 후 모든 job을 다시 가장 높은 queue로
- starvation과 changing-behavior를 해결 할 수 있다.
- 주기적으로 시스템의 모든 job의 priority를 높은 쪽으로
- Starvation 문제
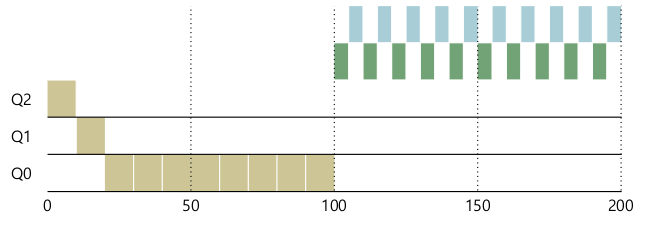
- Priority boost로 해결
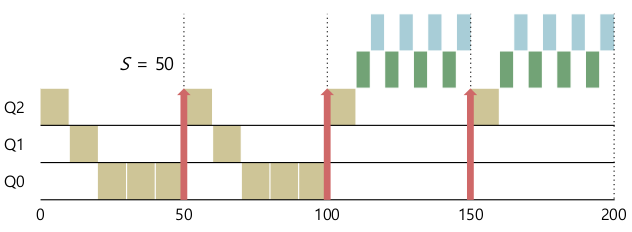
- Priority boost로 해결
- Gaming the scheduler 문제
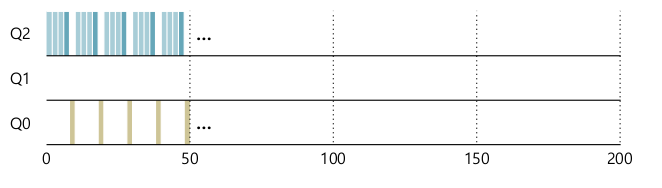
- Rule 4를 재정의하자.
- 누적된 CPU 사용량이 time slice만큼 되는가?
- 누적된 사용량이 time slice만큼 된다면 priority를 낮추자
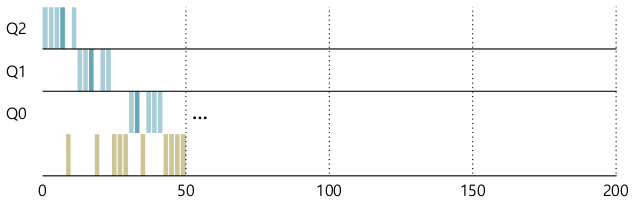
- Rule 4를 재정의하자.
- Changing bevaior 문제
- Priority boost
- 우선순위가 높은 큐에 머무를 기회가 많아진다.
- Priority boost
Multiprocessor
(1)
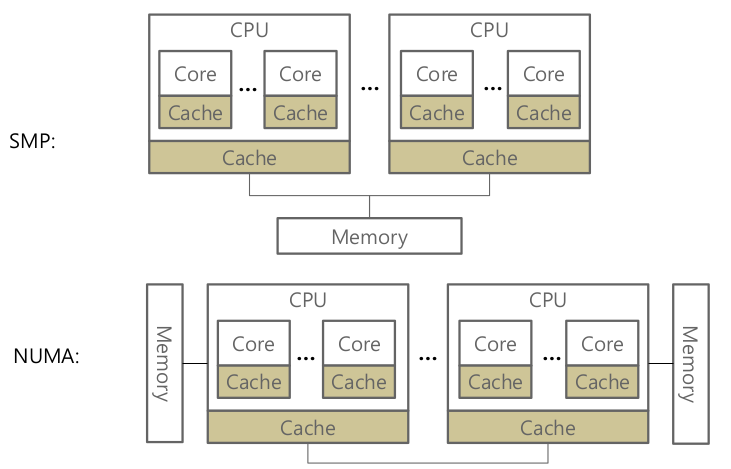
- SMP (Sementric Multi processing)
- System Bus, Memory Bus에 트래픽이 많아진다.
- 코어가 많아지고, 프로세스와 쓰레드가 많아지므로
- NUMA
- CPU 패키지마다 다른 메모리 액세스
- laptop, desktop은 보통 CPU 패키지 1개임 ..
- 다른 CPU 패키지에서 쓰는 메모리를 접근할 수 있다.
- malloc 같은 api는 운영체제가 어느 cpu에 할지 결정.
- cache는 원본의 복사본.
- consistency 문제가 있을 수 있으니 해당 프로토콜이 존재한다. (MESI)
- CPU 패키지마다 다른 메모리 액세스
- Single-Queue scheduling: Single-queue multiprocessor scheduling (SQMS)
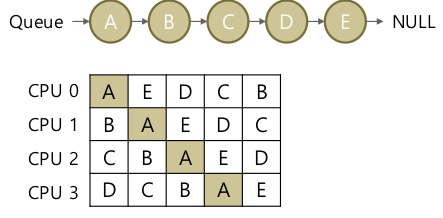
- CPU 가 여러개여도 Ready Queue는 1개.
- 지금까지의 CPU 스케쥴링은 그대로 쓸 수 있다.
- n개의 job을 꺼내올 수 있다. (n = CPUs)
- A가 0->1->2->3 … Cache affinity(캐시 친화도)가 구리다.
- (CPU마다 클락이 다르다 등의 이유로) time slice가 다를 수 있다. (끝나는 시점이 다를 수 있다.)
- queue에 접근할 때 동기화 필요.
- critical section이 생기므로 공유되는 메모리 영역, sequential 할 수 밖에 없다.
- scalability가 구려진다.
- Queue 하나가 간단할 수 있지만 여러 단점들이 존재한다.
- CPU 가 여러개여도 Ready Queue는 1개.
- Multi-Queue Scheduling: Multi-queue multiprocessor scheduling (MQMS)
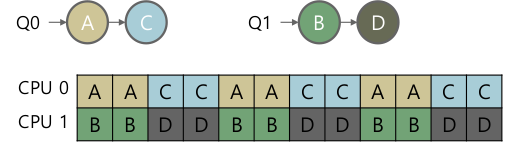
- CPU마다 Ready queue를 따로 두자.
- job이 시스템에 arrive 할때, 하나의 queue에만 존재하자.
- 어떤 큐에 둘것인가? random, shorter queue, …
- 독립적으로 Ready queue에 접근, 스케쥴링
- 하나의 큐 - 하나의 CPU. 따라서 동기화가 필요 없다.
- 1 job은 계속 같은 CPU에서 돈다. locality도 좋다.
- Load imbalance 문제
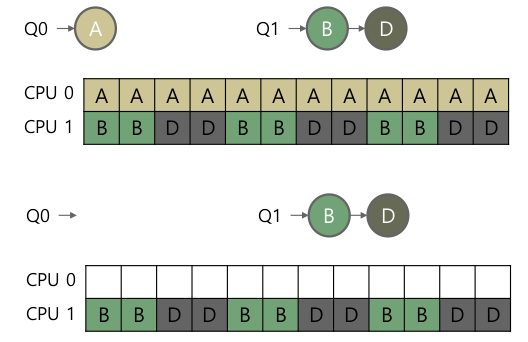
- 어떻게 하지?
- Migration : job 을 다른 큐로 옮기자. 누가? 언제?
- Work stealing
- CPU가 한가해지면 다른 큐에서 job을 가져온다. 밸런스를 맞춰보자.
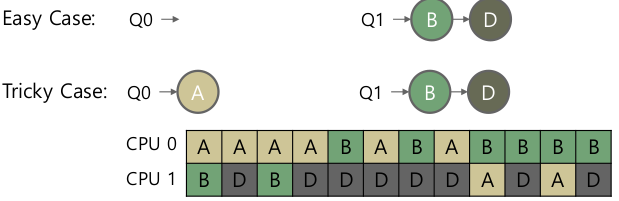
- 일반적으로 메모리 bound가 적은 놈을 가져온다.
- CPU가 한가해지면 다른 큐에서 job을 가져온다. 밸런스를 맞춰보자.
- 어떻게 하지?
(2)
- Linux CPU schedulers
- Completely Fair Scheduler (CFS)
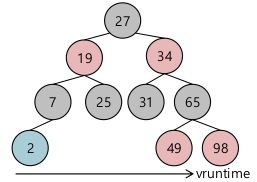
- Red-Black tree
- default (SCHED_NORMAL)
- weighted fair scheduling
- 프로세스가 얼마나 CPU를 점유하고 이ㅣㅆ었는지,
- 가장 적게 점유한 애가 최하단 왼쪽, 얘를 우선으로 하려고 노력한다.
- Real-Time Scheduler
- Multilevel Feedback Queue와 유사.
- SCHED_FIFO, SCHED_RR
- Priority-based scheduling
- priority가 고정되어 있다. (동적으로 변하지 않음). 우선순위 조정 필요
- sched_setattr
- Deadline Scheduler
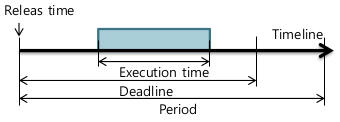
- SCHED_DEADLINE
- EOF(Earliest Deadline First)-like scheduler
- Deadline이 제일 급한 애부터 실행시켜라
- Period(주기)마다 실행하는데, 정해진 Execution time 만큼 실행한다.
- sched_setattr
- Completely Fair Scheduler (CFS)
- Completely Fair Scheduler (CFS)
- vruntime
- red-black tree에 얼만큼 job이 실행됐는지 저장된다. virtual runtime 기준.
- 각각의 job 마다 nice value가 있어서 runtime에 따라서 weight값을 부여
- nice: -20 ~ 19
- nice가 높으면 CPU 자원을 적게 사용하도록, 낮으면 CPU 자원을 많이 사용하도록 스케쥴러가 동작. $$ vruntime = vruntime + DeltaExec * Weight_0 / Weight_p $$
- DeltaExec: 최근 실행시간
- vruntime
/proc/<pid>/sched- priority
- prio = nice + 120
- CFS: 100 ~ 139
- 0 ~ 99 는 real-time scheduler 를 위해 reserved.
- prio = nice + 120
- renice
- 막바꾸면 안된다.
- -1~-20: root 만 rksmd
- priority
- Multiprocessor Scheduling in CFs
- Load metric
- Load of thread: 각 쓰레드가 단위 시간당 CPU를 사용한 시간 평균. priority, weighted 고려
- Load of core: loads of the threads 합
- 코어 별 로드를 균일하게 맞추고자 한다. 4ms마다.
- Imbalance라고 판단되면 고려할 것
- Cache.. 코어마다 다른 캐시
- NUMA… CPU 패키지별로 메모리, 버퍼 할당.
- CPU 패키지별로 load diff가 25% 보다 작으면 migration, load balancing 하지 않음.
- Load metric
Memory Virttualization
Concurrency
Threads
(1)
- Multi-threaded
- Multi process와 유사한 성격
- 자신만의 Program counter, 레지스터
- 스레드마다 스택
- 한 프로스세내 스레드들은 address space 공유
- Context switch
- TCP (Thraed Control Block), 리눅스에선 PCB, TCP 구분이 없다.
- Address space에 해당하는 부분은 그대로 둔다. (CR3 레지스터가 바뀌지 않는다.)

- Multi process와 유사한 성격
- Why use threads?
- Parallelism, 병렬성
- Multiple core CPU가 계속 등장하고 있다.
- Avoiding blocking
- Slow I/O
- main thread만 있고, I/O block되면 다른 일을 못한다.
- 다른 thread가 있고 다른 종류의 일을 실행할 수 있다면 성능 향상
- 많은 서버 application이 multi-threaded 다.
- Parallelism, 병렬성
- Thread creation
- pthread_create
- pthread_join: watis for the threads to finish
- Nondeterministic: 실행순서는 예측할 수 없음
(2)
- Race condition

- Critical section
- 공유되는 자원, 공유되는 변수들
- 반드시 1개의 thread 에서만 접근.
- Mutual exclusion
- critical section에서 1개의 thread만 접근함을 보장
- Atomicity
- critical section 구간 자체를 interrupt가 발생하지 않도록 만든다.
- 어떤 instruction이 중간에 interrupt 발생시 실행을 안하게, 또는 발생했음에도 instruction이 끝날때 까지 interrupt를 처리하지 않도록
- How to support synchronization
- 하드웨어 제공 (atomic instructions)
- Atomic memory add: 대부분 CPU 제공.
- 자료구조는? Atomic update of B-Tree? CPU가 제공하기 어렵다. 회로도 복잡하고, Atomic 오버헤드.
- OS가 Atomic instruction을 기반으로 좀 더 일반적인 동기화 primitives (system call) 를 제공
- 하드웨어 제공 (atomic instructions)
- Mutex
- pthread_mutex_lock
- pthread_mutex_unlock
- pthread_mutex_trylock
- pthread_mutex_timedlock
- Initialization
- Static
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; - Dynamic
int rc = pthread_mutex_init(&lock, NULL);
- Static
- Destory
pthread_mutex_destroy()
- Condition varibales
- pthread_cond_wait
- pthread_cond_signal
- 어떤 상태가 다른 CPU에 의해 바뀌었음을 인지하고, 바뀌었을 때 나에게 signal을 보내서 꺠워줄 수 있는 역할.
- Synchronizing two threads
while (ready == 0) ; // spinready = 1;- spin lock, busy wait: CPU 낭비. 어떤 상태가 되기까지 기다리겠다.
- CPU cycle 낭비. 1 core CPU라면 thread 1 점유. 상태가 바뀌지도 않을텐데.
- 서로 다른 core라면
- 다른 CPU cache에 ready 값이 들어간다. 값 update를 알아차리기 위해 CPU 종류에 따른 cache coherence 알고리즘 의존적
- compiler optimization은?
- Condtition variable 활용
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t cond = PTHREAD_COND_INITIALIZER; pthread_mutex_lock(&lock); while (ready == 0) pthread_cond_wait(&cond, &lock); pthread_mutex_unlock(&lock);Pthread_mutex_lock(&lock); ready = 1; Pthread_cond_signal(&cond); Pthread_mutex_unlock(&lock);- Compile
gcc -o main main.c -Wall -pthread
Locks
- Pthread Locks
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
...
pthread_mutex_lock(&lock);
counter = counter + 1; // critical section
pthread_mutex_unlock(&lock);
- lock을 어떻게 구현하지?
- 하드웨어 support는?
- OS의 역할은?
- Evaluation Locks
- Mutual exclusion (제일 중요)
- critical section 내에 1개의 thread만 진입
- Fairness
- lock 취득에 있어 fair한 순서보장
- Performance
- lock을 함에 따라 성능 하락이 있진 않은지
- thread 수, CPU 수에 따라 성능의 impact는?
- Mutual exclusion (제일 중요)
- Controlling Interrupts
void lock() {
DisableInterrupts();
}
void unlock() {
EnableInterrupts();
}
- 프로세스 스케쥴링에 있어 가장 중요한건 timer interrupt.
- Timer interrupt를 disable하면 timer interrupt가 발생하지 않음
- scheduling X, context switch X, race condition X
- 간단하지만 많은 단점
- privileged operation
- multiprocessor라면 통하지 않는다. (호출한 CPU만 Interrupt disable)
- interrupt 발생 가능성을 잃을 수 있다. 더 처리해야하는데, 덜 처리할 수 있다. 성능 저하 가능성
- 결정적으로 이런 시스템콜은 없다.
- Spin locks with Load/Stores
typedef struct __lock_t { int flag; } lock_t;
void init(lock_t *mutex) {
// 0 -> lock is available, 1 -> held
mutex->flag = 0;
}
void lock(lock_t *mutex) {
while (mutex->flag == 1)
;
mutex->flag = 1;
}
void unlock(lock_t *mutex) {
mutex->flag = 0;
}
| Thread 1 | Thread 2 |
|---|---|
| Call lock() | |
| while (flag == 1)? | |
| Context switch | |
| Call lock() | |
| while (flag == 1)? | |
| flag = 1; | |
| Context switch | |
| flag = 1; |
- No mutual exclusion
- Performance Problem
- waste time waiting
(2)
- Spin locks
- Test-and-set atomic instruction
- 슈도코드. 실제로는 instruction 임
int TestAndSet(int *old_ptr, int new) { int old = *old_ptr; // fetch old value at old_ptr *old_ptr = new; // store ’new’ into old_ptr return old; // return the old value }- 어떠한 preemption이 없음을 하드웨어가 보장
- Test-and-set atomic instruction
- Spin locks with Test-and-Set
typedef struct __lock_t { int flag; } lock_t;
void init(lock_t *lock) {
lock->flag = 0;
}
void lock(lock_t *lock) {
while (TestAndSet(&lock->flag, 1) == 1);
}
void unlock(lock_t *mutex) {
mutex->flag = 0;
}
- TestAndSet(0, 1) -> while 문을 빠져나감. lock 취득
- TestAndSet(1, 1) -> 계속 while.
- 문제점
- Not fair
- 성능.
- single core -> thread가 많아지면 더 심각해짐.
- unlcok 되기전에 ready queue에 들어가면?
- Compare-and-swap atomic instruction
int CompareAndSwap(int *ptr, int expected, int new) {
int actual = *ptr;
if (actual == expected)
*ptr = new;
return actual;
}
void lock(lock_t *lock) {
while (CompareAndSwap(&lock->flag, 0, 1) == 1);
}
- CompareAndSwap(0, 0, 1) -> while문 빠져나감. lock 취득
- CompareAndSwap(1, 0, 1) -> 계속 while 대기
- 달라진 건 없다.
- Mutex O
- Fair X
- Performance X
- Ticket locks: 티켓을 나눠주고 돌려받는 대로.
- fetch-and-add atomic
int FetchAndAdd(int *ptr) { int old = *ptr; *ptr = old + 1; return old; }typedef struct __lock_t { int ticket; int turn; } lock_t; void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; } void lock(lock_t *lock) { int myturn = FetchAndAdd(&lock->ticket); while (lock->turn != myturn); } void unlock(lock_t *lock) { lock->turn = lock->turn + 1; }- Fair O
- fetch-and-add atomic
- Hardware support
- Too much spinning
- 성능관점 문제가 남아있다.
- A simple approach
- yield()
- CPU 자원을 포기하겠다. 다른 thread를 실행시켜라.
- 다만 scheduler는 다시 실행시킬 수 있다. vruntime등의 이유로
- 성능 관점에서 여전히 좋지 않다.
void lock(lock_t *lock) { while (TestAndSet(&lock->flag, 1) == 1) yield(); }- 많은 thread가 round-robin 기반으로 schedule 된다면? vruntime 계산해봤더니 결국 그대로.
- spinning은 해결되지 않는다. 결국 같은 thread들이 반복해서 yield. => OS가 중요해진다.
- yield()
- Too much spinning
(3)
- OS Support
- Sleeping instead of spinning
- Solaris
- park(): 호출 thread를 재운다.
- unpark(threadID): 해당 thread를 꺠운다.
- Linux
- futex: fast user-level mutex
- futex_wait(address, expected)
- futex_wake(address): 잚든 thread를 꺠운다.
- address: lock variable
- queue 기반으로 재우고 꺠운다.
- Solaris
- Sleeping instead of spinning
- Lock with queue
- queue: lock을 기다리는 queue
typedef struct __lock_t {
int flag; // lock
int guard; // spin-lock around the flag and
// queue manipulations
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1);
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park(); // ** wakeup/waiting race **
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1);
if (queue_empty(m->q))
m->flag = 0;
else
unpark(queue_remove(m->q));
m->guard = 0;
}
- TestAndSet ~ m->guard = 0 까지 atomic block.
- unpark() => park() 하면?
- lock 호출 주체가 park()하기 전에, lock 을 가지고 있던 놈이 unpark()
- 개선안.
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1);
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
setpark(); // another thread calls unpark before
m->guard = 0; // park is actually called, the
park(); // subsequent park returns immediately
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1);
if (queue_empty(m->q))
m->flag = 0;
else
unpark(queue_remove(m->q));
m->guard = 0;
}
- setpark() : unpark 호출이력 확인. 있는 경우 park()는 재우지 않음.
Lock-based Concurrnet Data Structures
여러 개의 쓰레드가 접근하는 공유 자료구조
race condition을 해결할 방법들
(1)
Correctness
- race condition을 발생시키지 않도록 lock
Concurrency
- lock을 걸게 되면 performance 하락 (병렬성 저하)
- 최대한 효율적으로 쓸 방법은?
Concurrent Counters
typedef struct __counter_t {
int value;
pthread_mutex_t lock;
} counter_t;
void init(counter_t *c) {
c->value = 0;
pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t *c) {
pthread_mutex_lock(&c->lock);
c->value++;
pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t *c) {
pthread_mutex_lock(&c->lock);
c->value--;
pthread_mutex_unlock(&c->lock);
}
int get(counter_t *c) {
pthread_mutex_lock(&c->lock);
int rc = c->value;
pthread_mutex_unlock(&c->lock);
return rc;
}
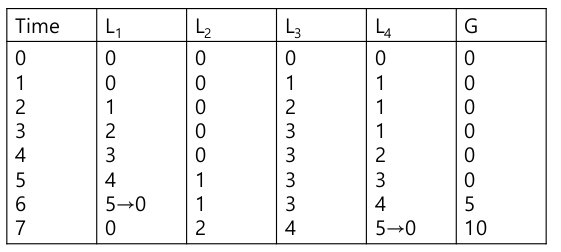
- Sloppy counter
- Logical counter
- CPU core 별 logical counter
- Global counter
- Locks (각 local counter 별 하나씩, global counter 하나)
- Basic idea
- 각 CPU가 local counter를 갖고 있고, local counter에 있어선 중간 operation을 다른 core와 경쟁없이 반영.
- 주기적으로 global counter에 반영
- 자주 하면 sloppy counter의 장점이 퇴색, 드문드문하면 정확성 하락
- 임계 값을 정하는 것이 중요
- Example
- Logical counter
typedef struct __counter_t {
int global;
pthread_mutex_t glock;
int local[NUMCPUS];
pthread_mutex_t llock[NUMCPUS];
int threshold; // ** update frequency **
} counter_t;
void init(counter_t *c, int threshold) {
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
int i;
for (i = 0; i < NUMCPUS; i++) {
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
void update(counter_t *c, int threadID, int amt) {
int cpu = threadID % NUMCPUS;
pthread_mutex_lock(&c->llock[cpu]); // local lock
c->local[cpu] += amt; // assumes amt > 0
if (c->local[cpu] >= c->threshold) {
pthread_mutex_lock(&c->glock);
c->global += c->local[cpu];
pthread_mutex_unlock(&c->glock);
c->local[cpu] = 0;
}
pthread_mutex_unlock(&c->llock[cpu]);
}
int get(counter_t *c) {
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate!
}
get의 정확성이 떨어진다. local counter update가 그때 그때 반영이 안되서. 성능은 좋아졌다.
(2)
- Concurrent Linked Lists
typedef struct __node_t {
int key;
struct __node_t *next;
} node_t;
typedef struct __list_t {
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; // fail
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; // success
}
int List_Lookup(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1; // failure
}
Critical section이 너무 크다.
- Scaling LinkedList
- 공유자원 접근하는 부분만 lock 하자.
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
void List_Insert(list_t *L, int key) {
// synchronization not needed
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
}
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv; // bug pruning
}
- Concurrent Queues
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t)); // dummy node
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
- Concurrent Hash Table
#define BUCKETS (101)
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
int i;
for (i = 0; i < BUCKETS; i++)
List_Init(&H->lists[i]);
}
int Hash_Insert(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
Condition Variables
Condition을 기다리는 방법.
- How to wait for a condition?
- Spinning은 CPU 낭비.
volatile int done = 0; void *child(void *arg) { printf("child\n"); done = 1; return NULL; } int main(int argc, char *argv[]) { pthread_t c; printf("parent: begin\n"); pthread_create(&c, NULL, child, NULL); // create child while (done == 0); // spin printf("parent: end\n"); return 0; } - Condition Variable
- Thread가 어떤 상태를 기다리는 데, 상태가 만족되지 않는 시간은 sleep (특정 큐에 들어간다.)
- 다른 Thread가 꺠울 수 있다.
- ptrhead_cond_wait(queue, mutex)
- 어떤 조건이 만족되지 않을때 만족되기까지 기다린다.
- 함수내에서 unlock, sleep
- pthread_cond_signal()
- 이때 다시 lock, wait에선 return
- Example
int done = 0; pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t c = PTHREAD_COND_INITIALIZER; void *child(void *arg) { printf("child\n"); thr_exit(); return NULL; } int main(int argc, char *argv[]) { pthread_t p; printf("parent: begin\n"); pthread_create(&p, NULL, child, NULL); thr_join(); printf("parent: end\n"); return 0; }void thr_exit() { pthread_mutex_lock(&m); done = 1; pthread_cond_signal(&c); pthread_mutex_unlock(&m); } void thr_join() { pthread_mutex_lock(&m); while (done == 0) pthread_cond_wait(&c, &m); pthread_mutex_unlock(&m); }- State varibale이 없다면
void thr_exit() { pthread_mutex_lock(&m); pthread_cond_signal(&c); pthread_mutex_unlock(&m); } void thr_join() { pthread_mutex_lock(&m); pthread_cond_wait(&c, &m); pthread_mutex_unlock(&m); }- Wait 하기전에 Signal.
- main threada를 깨울 애가 없어진다.
- 따라서 state variable이 필요하다.
- Lock이 없다면
void thr_exit() { done = 1; pthread_cond_signal(&c); } void thr_join() { while (done == 0) pthread_cond_wait(&c); }- 마찬가지로 Wait 하기전에 signal.
(2)
- Producer / Consumer Problem
- Producer: 데이터 생산 thread
- Consumer: 데이터 소비 thread
- Example
- Pipe
- Web server
- bounded buffer (큐의 길이가 한정적) 가 shared resouce 니까, 동기화가 필요하다. Condition variable 쓰자.
- Example
int buffer; // single buffer
int count = 0; // initially, empty
void put(int value) {
assert(count == 0);
count = 1;
buffer = value;
}
int get() {
assert(count == 1);
count = 0;
return buffer;
}
- Example - if
- Producer
cond_t cond; mutex_t mutex; void *producer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); if (count == 1) pthread_cond_wait(&cond, &mutex); put(i); pthread_cond_signal(&cond); pthread_mutex_unlock(&mutex); } } - Consumer
void *consumer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); if (count == 0) pthread_cond_wait(&cond, &mutex); int tmp = get(); pthread_cond_signal(&cond); pthread_mutex_unlock(&mutex); printf("%d\n", tmp); } }
- Producer
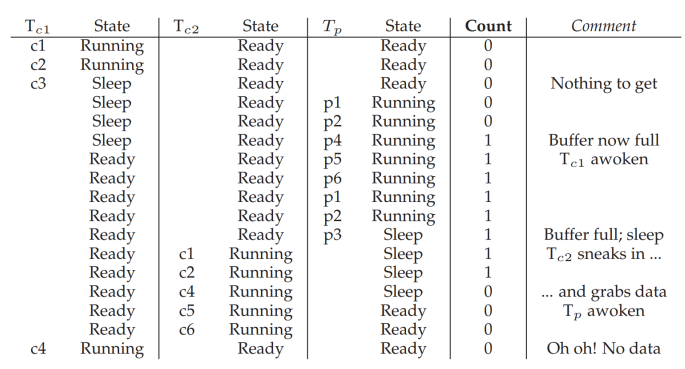 T(c1)이 wait, T(p)가 produce 했는데 T(c2)가 consume.
T(c1)이 wait, T(p)가 produce 했는데 T(c2)가 consume.
T(c1)이 일어나보니 데이터가 없다 -> error
- Example - while
- Producer
cond_t cond; mutex_t mutex; void *producer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); while (count == 1) pthread_cond_wait(&cond, &mutex); put(i); pthread_cond_signal(&cond); pthread_mutex_unlock(&mutex); } } - Consumer
void *consumer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); while (count == 0) pthread_cond_wait(&cond, &mutex); int tmp = get(); pthread_cond_signal(&cond); pthread_mutex_unlock(&mutex); printf("%d\n", tmp); } }
- Producer
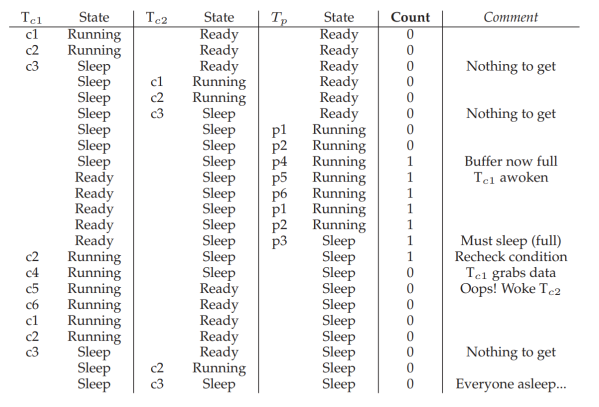 T(c1)이 sleep, T(c2)가 sleep, T(p)가 produce, signal, sleep
T(c1)이 sleep, T(c2)가 sleep, T(p)가 produce, signal, sleep
T(c1)이 comsume 하고 sleep. producer를 꺠우려 했는데 consumer가 깨어났다.
T(c2). 일어나보니 data가 없다.
같은 condition variable이라는 게 문제.
- Example - while & Two CVs
- Producer
cond_t empty, fill; mutex_t mutex; void *producer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); while (count == 1) pthread_cond_wait(&empty, &mutex); put(i); pthread_cond_signal(&fill); pthread_mutex_unlock(&mutex); } } - Consumer
void *consumer(void *arg) { int i; for (i = 0; i < loops; i++) { pthread_mutex_lock(&mutex); while (count == 0) pthread_cond_wait(&fill, &mutex); int tmp = get(); pthread_cond_signal(&empty); pthread_mutex_unlock(&mutex); printf("%d\n", tmp); } }
- Producer
(3)
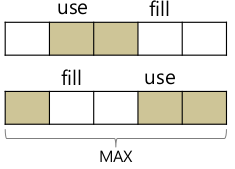
- More concurrency
int buffer[MAX];
int fill_ptr = 0;
int use_ptr = 0;
int count = 0;
void put(int value) {
buffer[fill_ptr] = value;
fill_ptr = (fill_ptr + 1) % MAX;
count++;
}
int get() {
int tmp = buffer[use_ptr];
use_ptr = (use_ptr + 1) % MAX;
count--;
return tmp;
}
cond_t empty, fill;
mutex_t mutex;
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
pthread_mutex_lock(&mutex);
while (count == MAX)
pthread_cond_wait(&empty, &mutex);
put(i);
pthread_cond_signal(&fill);
pthread_mutex_unlock(&mutex);
}
}
void *consumer(void *arg) {
int i, tmp;
for (i = 0; i < loops; i++) {
pthread_mutex_lock(&mutex);
while (count == 0)
pthread_cond_wait(&fill, &mutex);
tmp = get();
pthread_cond_signal(&empty);
pthread_mutex_unlock(&mutex);
printf("%d\n", tmp);
}
}
- Covering conditions
- 모든 thread를 꺠워야 할 수도
- pthread_cond_broadcast()
- example
- Multi-threaded memory allocation library
Semaphores
(1)
lock과 condition variable 두 목적으로 쓸 수 있다.
- POSIX
sem_init(sem_t *s, int pshared, unsigned int value)- semaphore init
- 초기값 value 존재
- pshared - 0이면 thread에서 공유, 0이 아니면 process끼리 공유. “shared memory”
- sem_wait(sem_t *s)
- s 값을 1씩 줄인다.
- s가 음수면 프로세스를 큐에 재운다.
- sem_post(sem_t *s)
- s 값을 1 증가
- sleep 된 프로세스가 있다면 꺠운다.
- Binary semaphore
sem_t m;
sem_init(&m, 0, 1);
sem_wait(&m);
// critical section here
sem_post(&m);
- condition lock 대체 가능

- Semaphores for ordering
sem_t s;
void * child(void *arg) {
printf("child\n");
sem_post(&s);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t c;
sem_init(&s, 0, X); // what should X be?
printf("parent: begin\n");
pthread_create(&c, NULL, child, NULL);
sem_wait(&s);
printf("parent: end\n");
return 0;
}
- 초기값을 뭐로 하지? lock 대신이면 1.. 0을 줄수도 있다.

(2)
- Producer/Consumer Problem
int buffer[MAX]; // bounded buffer
int fill = 0;
int use = 0;
void put(int value) {
buffer[fill] = value;
fill = (fill + 1) % MAX;
}
int get() {
int tmp = buffer[use];
use = (use + 1) % MAX;
return tmp;
}
sem_t empty, sem_t full;
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty);
put(i);
sem_post(&full);
}
}
void *consumer(void *arg) {
int i, tmp = 0;
while (tmp != -1) {
sem_wait(&full);
tmp = get();
sem_post(&empty);
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]) {
// ...
sem_init(&empty, 0, MAX); // MAX are empty
sem_init(&full, 0, 0); // 0 are full
// ...
}
- Race condition
- Single thread producer / cocnsumer 라면 동작
- multi thread의 경우 put(), get() 에서 race condition
- producer, consumer를 mutex 로 감싼다.
void *producer(void *arg) { int i; for (i = 0; i < loops; i++) { sem_wait(&mutex); sem_wait(&empty); put(i); sem_post(&full); sem_post(&mutex); } } void *consumer(void *arg) { int i; for (i = 0; i < loops; i++) { sem_wait(&mutex); sem_wait(&full); int tmp = get(); sem_post(&empty); sem_post(&mutex); } }
- Deadlock
- 2개 이상 thread에서
- 테스트케이스보단 production 경험.
- 동기화는 설계부터 고려되어야 한다.
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty);
sem_wait(&mutex);
put(i);
sem_post(&mutex);
sem_post(&full);
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&full);
sem_wait(&mutex);
int tmp = get();
sem_post(&mutex);
sem_post(&empty);
}
}
(3)
- Reader-Writer Locks
- write 보다 read가 훨씬 많더라.
- Reader
- rwlock_acquire_readlock()
- rwlock_release_readlock()
- Writer
- rwlock_acquire_writelock()
- rwlock_release_writelock()
typedef struct _rwlock_t {
// binary semaphore (basic lock)
sem_t lock;
// used to allow ONE writer or MANY readers
sem_t writelock;
// count of readers reading in critical section
int readers;
} rwlock_t;
void rwlock_init(rwlock_t *rw) {
rw->readers = 0;
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void rwlock_acquire_writelock(rwlock_t *rw) {
sem_wait(&rw->writelock);
}
void rwlock_release_writelock(rwlock_t *rw) {
sem_post(&rw->writelock);
}
writer starvation 문제가 있을 수 있다.
void rwlock_acquire_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers++;
if (rw->readers == 1)
// first reader acquires writelock
sem_wait(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_release_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers--;
if (rw->readers == 0)
// last reader releases writelock
sem_post(&rw->writelock);
sem_post(&rw->lock);
}
- How to implement semaphores
typedef struct __Sem_t {
int value;
pthread_cond_t cond;
pthread_mutex_t lock;
} Sem_t;
// only one thread can call this
void Sem_init(Sem_t *s, int value) {
s->value = value;
Cond_init(&s->cond);
Mutex_init(&s->lock);
}
void Sem_wait(Sem_t *s) {
Mutex_lock(&s->lock);
while (s->value <= 0)
Cond_wait(&s->cond, &s->lock);
s->value--;
Mutex_unlock(&s->lock);
}
void Sem_post(Sem_t *s) {
Mutex_lock(&s->lock);
s->value++;
Cond_signal(&s->cond);
Mutex_unlock(&s->lock);
}
- 원래 표준: value를 줄이고 음수면 잠든다. (number: 자고 있는 스레드 수)
- 리눅스 구현: value는 0보다 작아질 수 없다.
- 더 자세히) Linux는 condition variable이 아닌 futex로 구현.
Common Concurrency Problems
(1)
- Concurrency Problems
- Non-deadlock bus
- Atomicity-violation bugs: critical section X
- Order-violation bugs: 순서 문제 해결 X
- Deadlock bugs
- Non-deadlock bus
- Atomicity-Violation Bugs
- race condition이 발생하지 않을 것이란 기대. 하지만 atomic이 보장되지 않았다.
- Example (MySQL)
Thread 1: if (thd->proc_info) { ... fputs(thd->proc_info, ...); ... } Thread 2: thd->proc_info = NULL;- Atomicity-Violation Fixed
pthread_mutex_t proc_info_lock = PTHREAD_MUTEX_INITIALIZER; Thread 1: pthread_mutex_lock(&proc_info_lock); if (thd->proc_info) { ... fputs(thd->proc_info, ...); ... } pthread_mutex_unlock(&proc_info_lock); Thread 2: pthread_mutex_lock(&proc_info_lock); thd->proc_info = NULL; pthread_mutex_unlock(&proc_info_lock);
- Order-Violation Bugs
- A가 항상 B 전에 실행될 것이란 기대
- Example
Thread 1: void init() { ... mThread = PR_CreateThread(mMain, ...); ... } Thread 2: void mMain(...) { ... mState = mThread->State; ... } - Order-Violation Fixed
- Thread 1
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER; int mtInit = 0; void init() { ... mThread = PR_CreateThread(mMain, ...); // signal that the thread has been created... pthread_mutex_lock(&mtLock); mtInit = 1; pthread_cond_signal(&mtCond); pthread_mutex_unlock(&mtLock); ... }- Thread 2
void mMain(...) { ... // wait for the thread to be initialized... pthread_mutex_lock(&mtLock); while (mtInit == 0) pthread_cond_wait(&mtCond, &mtLock); pthread_mutex_unlock(&mtLock); mState = mThread->State; ... }
(2)
- Deadlock Bugs
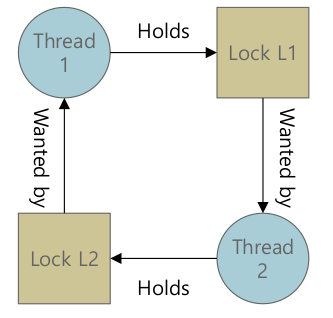
- Circular dependencies. 순환 참조
Thread 1: pthread_mutex_lock(L1); pthread_mutex_lock(L2); Thread 2: pthread_mutex_lock(L2); pthread_mutex_lock(L1); - Why do deadlocks occur?
- 코드가 크니 일일히 찾기 쉽지 않다.
- Example (virtual memory system)
- VMS -> FS
- FS -> VMS
- 자주 읽는 데이터는 Intermediate Buffer 안에. (Buffer cache, Page cache)
- Circular request
- Nature of encapsulation
- Example (Java vector class)
Vector v1, v2; Thread 1: v1.AddAll(v2); Thread 2: v2.AddAll(v1); `` - vector 내에서 lock이 잘 되어 있어도 deadlock이 발생함을 알기 어렵다.
- Example (Java vector class)
- Conditions for Deadlocks
- Mutual exclusion
- race condition을 없애기 위해 만든 lock이지만 그로 인해 deadlock이.
- Hold-and-wait
- lock을 가진채로 다른 lock을 얻으려 한다.
- No preemption
- 다른 thread가 갖는 lock을 강제로 뺏어 올 수가 없다.
- Circular wait
- lock을 기다리는 구조가 circular
- 이 네가지가 모두 만족 되었다면 circular
- 1가지만 피하면 deadlock을 피할 수 있다.
- Mutual exclusion
- Deadlock prevention
- Circular wait
- lock acquire 순서가 다르면서 circular
Thread 1: lock(L1); lock(L2); Thread2: lock(L2); lock(L1); - 그렇다면 lock acquire 순서가 모두 같으면 circular wait이 발생하지 않는다.
- partial ordering
- lock acquire 순서가 다르면서 circular
- Hold-and-wait
- 모든 lock을 한꺼번에 acquire
pthread_mutex_lock(prevention); // begin lock acquisition pthread_mutex_lock(L1); pthread_mutex_lock(L2); ... pthread_mutex_unlock(prevention); // end - critical section이 커진다.
- lock을 모두 알고 있어야 한다.
- -> 모든 상황에 적용은 어렵다.
- 모든 lock을 한꺼번에 acquire
- No preemption
- 현재 대부분의 운영체젱서 강제로 뺏어 올 수 있는 방법은 없다.
- 현실적 solution: trylock
top: pthread_mutex_lock(L1); if (pthread_mutex_trylock(L2) != 0) { pthread_mutex_unlock(L1); goto top; } - 내가 L1, L2 둥다 못가져 온다면 둘다 포기하고 다시 처음부터 acquire.
- livelock
- 여러 thread가 모든 lock을 acquire 하지 못한 채로 loop
- solution: goto 하기 전에 random delay
- 주의점: goto 하기 전에 unlock. 자원 획득하기 전에 release 필요.
- mutual excclusion
- Lock-free approaches. Lock-free 알고리즘을 쓰자.
void insert(int value) { node_t *n = malloc(sizeof(node_t)); assert(n != NULL); n->value = value; pthread_mutex_lock(listlock); n->next = head; head = n; pthread_mutex_unlock(listlock); } - CompareAndSwap과 같은 atomic instruction을 쓸 수 있겠다.
void insert(int value) { node_t *n = malloc(sizeof(node_t)); assert(n != NULL); n->value = value; do { n->next = head; } while (CompareAndSwap(&head, n->next, n) == 0); } - CPU 자원 낭비 가능성, thread가 많아지면 효율이 구려진다.
- Lock-free approaches. Lock-free 알고리즘을 쓰자.
- Circular wait
- Deadlock Avoidance
- 쉽지 않다.
- 여기저기 쓸 수 있는 방법은 아니다.
- 쉽지 않다.
- Detect and recover
- deadlock이 발생했을때 detect and recover?
- 어려운 기술. trace가 가능한가?
- 무엇을 recove? checkpoint??
- Restart !!
Persistency
I/O devices and HDD
(1)
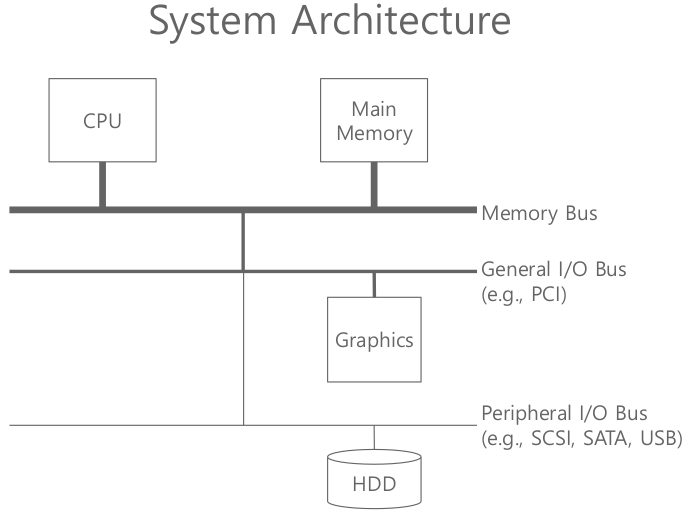
Interface: Device Driver
- 시스템 소프트웨어가 명령을 어떤 식으로 넘겨줄 것인가.
- interface, protocol 정의
- (같은 제품이라도 vendor에 따라 드라이버가 바뀐다.)
Internal structure

- status: 상태 알려준다
- command, data: OS 드라이버가 어떤 커맨드를 넘겨줄지 셋팅
- internals: 실행해야하는 코드 존재. firmware 또는 OS
Protocol
While (STATUS == BUSY) ; // wait until device is not busy Write data to DATA register Write command to COMMAND register (Doing so starts the device and executes the command) While (STATUS == BUSY) ; // wait until device is done with your request- 비효율적
- Polling: CPU 자원 낭비
- Programmed I/O (PIO)
- CPU가 일일히 write??
- 메모리 접근보다 오래걸린다.
- Interrupts
- Polling하는 대신 CPU는 request
- 요청한 process는 잠들게 만들고 context switch
- hardware적으로 일이 끝나면 Interrupt
- Interrupt handler가 호출: ISR(Interrupt Service Routine), blocked process가 ready로, 나중에 scheduler에 의해 실행
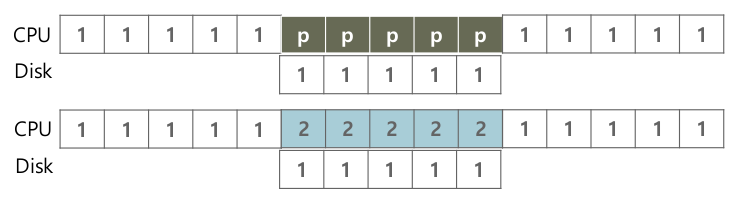
- Interrupt handler가 호출: ISR(Interrupt Service Routine), blocked process가 ready로, 나중에 scheduler에 의해 실행
- Polling하는 대신 CPU는 request
- 비효율적
Direct Memory Access (DMA)
- PIO 문제 해결하기 위해
- DMA Engine을 사용해 데이터 이동, CPU가 데이터 이동에 관여하지 않는다.
- I/O device에 장착
- (CPU와 별도로) 메인메모리에서 자신의 디바이스로 데이터 이동 혹은 디바이스 데이터 -> 메인메모리
- OS 디바이스 드라이버에서 DMA 명령
- Data: 시작주소, 길이
- 해당 메모리주소는 물리주소.
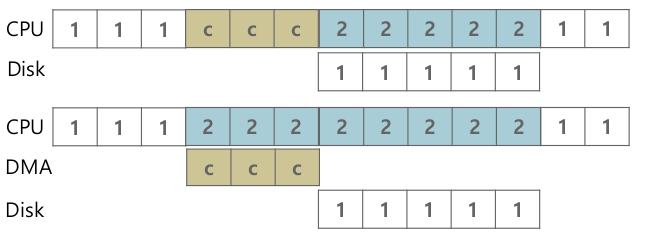
Methods of Device Interation
- 꼭 DMA, interrupt가 효율적인 것은 아니다.
- 별도의 I/O instructions
- in, out registers
- in, out을 통해 device의 특정 register에 값을 쓸 수 있다.
- 일반적으로 privileged
- I/O device 레지스터 이름은 vendor마다 다를텐데…
- Memory-mapped I/O
- device 메모리 영역(레지스터 포함)을 일종의 address space에 mapping
- 맵핑하고 나면 메모리 접근 할 때 주소로 접근 -> load/store
- 어느게 꼭 좋다고 할수 없다.
Device drivers

- 실제 storage들은 Block device. write/read 단위가 block이다. 보통 512 bytes
(2)
- Hard Disk Drives (HDD)
- Platter
- 데이터가 저장된 판떼기. (동그란 원판)
- HDD 안에 여러개 존재.
- Spindle
- platter가 연속된 중심 축. 계속해서 돈다.
- 회전속도에 따라 빠른 hardware / 느린 hardware
- roatation per minute (RPM)
- Track
- 선. 데이터들이 저장된 원판의 트랙. sector로 나눈다. (block이라 부른다). 512 bytes
- Disk head and disk arm
- Track으로 가기 위해 arm이 움직이고, 특정 sector에 접근하기 위해 spindle이 돈다.
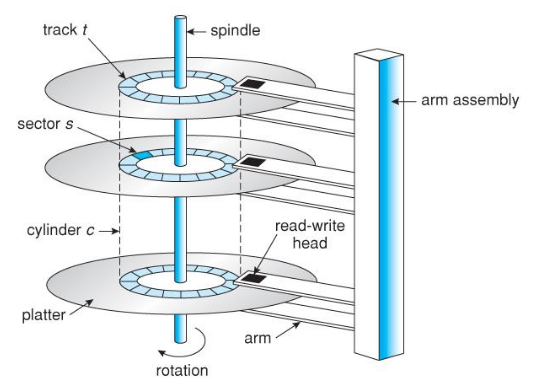
- Track으로 가기 위해 arm이 움직이고, 특정 sector에 접근하기 위해 spindle이 돈다.
- 요즘은 flash memory. 아직 classical server에서 HDD는 많이 쓰인다.
- Platter
- I/O Time
$$
T_{I/O} = T_{seek} + T_{rotation} + T_{transfer}
$$
- Seek time
- 원하는 트랙을 찾는 데 걸리는 시간
- Rotational Delay
- spindle이 회전함으로써 원하는 sector를 찾는 데 회전에 걸리는 시간
- Transfer time
- sector로 부터 head를 통해 data read/write에 걸리는 시간
- Seek time
- Disk Scheduling
- OS
- ms 단위의 시간. 컴퓨터 내에선 상당히 크다
- disk 접근 순서를 조정해서 $T_{rotation}$과 $T_{seek}$을 줄여서 전체 I/O time을 줄인다.
- Example
- Requests
- 98, 183, 37, 124, 65, 67 (Head starts at 53)
- FCFS (First come, First served)
- 98 -> 183 -> 37 -> 122 -> 14 -> 124 -> 65 -> 67
- Requests
- OS
- SSTF: Shortest Seek Time First
- sector 번호만 알고 track에 대한 구조는 모른다고 가정
- 가장 빨리 찾을 수 있는거를 찾자.
- Problems
- track에 대한 정보를 알 수 없다. 가장 가까이 있는 block을 찾는다. (sector 관점)
- starvation
- Example
- Requests
- 98, 183, 37, 124, 65, 67 (Head starts at 53)
- SSTF
- 64 -> 67 -> 37 -> 14 -> 98 -> 122 -> 124 -> 183
- 큐에 계속 가까이 있는 sector가 진입하면?
- starvation
- Requests
- Elevator
- SCAN
- ARM이 전진 중이라면 증가하는 쪽으로
- 높은 sector 번호에 다다르면 뒤쪽으로, 낮은 sector 번호를 읽는다.
- C-SCAN (높은 Sector 번호 -> 다시 제일 낮은 sector 번호)
- 바깥에서 안쪽으로만 읽고, 제일 높은 sector 번호까지 도착하면 제일 낮은 sector 번호로 다시.
- Problem
- Seek time만 고려하고, rotation time은 고려하지 않음.
- SCAN
- SPTF: Shortest Positioning Time First

- seek time, rotation time 모두 고려
- rotation time을 위해선 track 구조를 알아야한다.
- SPTF는 disk안에 firmware를 통해 구현되어 있다.
- 예시 그림
- rotation time이 더 크다면 8
- seek time이 더 크다면 16
Files and Directories
(1)
Abstractions for storage
- File
- byte의 연속적 array. byte단위로 접근할 수 있는 정보의 구조
- low-level name 존재: inode
- OS는 file의 위치는 알겠지만 이 file이 그림인지, text인지, C code 인지 모른다.
- OS가 판단하는 것이 아닌 Desktop level에서 확장자에 따라 연결 프로그램
- Directory
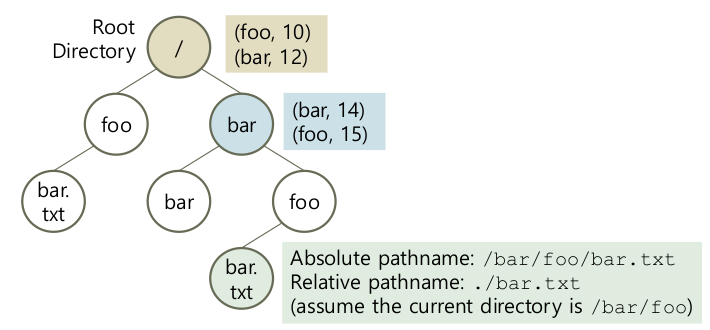
- 하위 file과 directory의 [user-readable name, indoe number] 쌍을 저장하는 정보
- 자기를 표현하기 위한 inode number 존재
- File
Creating Files
int fd = open("foo", O_CREAT|O_WRONLY|O_TRUNC, S_IRUSR|S_IWUSR);- O_TUNC: 이미 있으면 기존 내용 다 지우고 덮어쓴다
- S_IRUSR | S_IWUSR: readable, writable
File descriptor
- An integer
- 해당 프로세스는 read / write operation 수행 가능
- file에 대한 object pointer가 될 수 있다.
- 프로세스 마다 관리
- 각 프로세스마다 fd list
- An integer
Accessing Files (Random)
- OS는 “현재” offset 정보를 유지한다.
- Implicit update
- 내제적 업데이트
- N bytes read / write -> N만큼 offset 증가
- Read / Write 끝난 지점에 포인터가 가리킴.
- Explicit update
- 명시적 업데이트
- lseek 시스템콜로 앞으로도, 뒤로도 보낼 수 있다.
- lseek(int fd, off_t offset, int whence)
- whence
- SEEK_SET
- SEEK_CUR
- SEEK_END
- whence
Open File Table
- 프로세스 -> PCB -> open 되어 있는 파일 들의 정보
- 운영체제 -> open 되어 있는 파일 테이블
- 각각의 entry들은 PCB에서 관리하는 file descriptor와 1:1 맵핑
- Example (xv6) , xv6: 교육용 커널의 일종
struct { struct spinlock lock; struct file file[NFILE]; } ftable;struct file { int ref; // 보통 1이다. open한 채로 fork하면 2가 넘어갈 수도. char readable, writable; struct inode *ip; uint off; }; - file은 일반적으로 1개의 unique entry
- 동시에 같은 파일을 다른 프로세스에서 접근해도, 서로 다른 엔트리로 존재
- 각각의 file은 동일 파일을 open read / write해도 별도로 접근하는 것처럼 관리
- race condition 발생 가능성. mutex, semaphore 동기화 필요
(2)
- Shared File Entries
int main(int argc, char *argv[]) { int fd = open("file.txt", O_RDONLY); assert(fd >= 0); int rc = fork(); if (rc == 0) { rc = lseek(fd, 10, SEEK_SET); printf(“C: offset %d\n", rc); } else if (rc > 0) { (void) wait(NULL); printf(“P: offset %d\n", (int) lseek(fd, 0, SEEK_CUR)); } return 0; }prompt> ./fork-seek child: offset 10 parent: offset 10 prompt>- 다른 쪽에서 변경된 offset을 보도록 되어 있다.
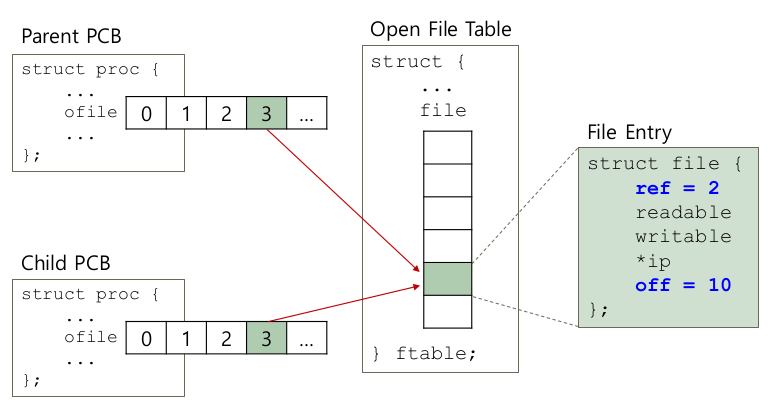
- dup() system call
- 인자로 넘어오는 fd와 동일한 파일 entry를 공유하는 fd를 하나 생성하겠다.
- 이때 return 되는 descriptor number는 현재 사용되지 않는 number 중 가장 낮은 descriptor number
- 인자로 넘어오는 fd와 동일한 파일 entry를 공유하는 fd를 하나 생성하겠다.
int fd=open(“output.txt", O_APPEND|O_WRONLY); close(1); dup(fd); //duplicate fd to file descriptor 1 printf(“My message\n"); - 다른 쪽에서 변경된 offset을 보도록 되어 있다.
- Writing Immediately
- write()
- 운영체제는 바로 disk에 쓰지 않는다. (상당한 overhead)
- 요청이 있을 때 마다 그때 그때 write하기 보다는 요청을 모아놨다가 한꺼번에 write. disk scheduling 효율을 올린다.
- 운영체제 buffering. (page cache / buffer cache)
- fsync()
- buffering이 하고 싶지 않을때.
- unlink(): 파일을 지우는 system call.
- write()
- Making Directories
- mkdir()
- 디렉토리가 만들어지면 비어있는 디렉토리.
- Default entries
.: 자기 자신..: 상위 디렉토리
- mkdir()
- Reading Directories
- opendir(), readdir(), closedir()
int main(int argc, char *argv[]) { DIR *dp = opendir("."); struct dirent *d; while ((d = readdir(dp)) != NULL) { printf("%lu %s\n", (unsigned long) d->d_ino, d->d_name); } closedir(dp); return 0; }struct dirent { char d_name[256]; // filename ino_t d_ino; // inode number off_t d_off; // offset to the next dirent unsigned short d_reclen; // length of this record unsigned char d_type; // type of file }; - rmdir()
- 디렉토리가 비어있어야 한다.
- 비어있지 않은 애를 지우려고 하면 함수 fail.
- opendir(), readdir(), closedir()
- Link and Unlink Fiels
- ln command, link() system call
prompt> echo hello > file prompt> cat file hello prompt> ln file file2 prompt> cat file2 Hello prompt> ls -i file file2 67158084 file 67158084 file2 prompt>- ln file, file2
- rm command, unlink() systemcall
prompt> rm file removed ‘file’ prompt> cat file2 hello
- ln command, link() system call
(3)
Mechanisms for resouce sharing
- Abstraction of a process
- CPU virtualization -> private CPU
- Memory virtualization -> private memory
- File system
- Disk virtualization -> files and directories
- block 단위로 데이터를 저장 / 제공하는 하드웨어 리소스
- 어떻게 하면 file과 directory라는 abstraction을 제공하지? -> File system
- protection이 중요해진다.
- permission bits
- Disk virtualization -> files and directories
- Abstraction of a process
Permission Bits
prompt> ls -l foo.txt -rw-r--r-- 1 remzi wheel 0 Aug 24 16:29 foo.txt- Type of file
- -: regular file
- d: directory
- l:: symbolic link
- Permision bits
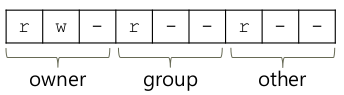
prompt> chmod 600 foo.txt
- Type of file
Making a file system
- 블락 단위의 하드웨어 자원을 file과 directory라는 abstraction으로 제공
- abstraction을 제공하기 위해 필요한 정보가 disk안에 쓰여져야 함
- mkfs: 파일 시스템을 깔아준다.
prompt> mkfs -t ext4 /dev/sda1- /dev/sda1: 다바이스. 실제로 이 경로로 가서 파일과 디렉토리가 보이는 건 아님.
- Unix에서 1 디바이스 - 1 파일
Mounting a file system
- 일반적으로 우리가 파일 / 디렉토리를 접근할 수 있도록 하기 위해서 File system tree와 연결이 필요
- file system이 만들어진 disk partition을 특정 파일 tree에 연결시켜 주어야 한다.
- 특정 file system을 설치한 block device를 system에 있는 file과 directory tree에 연결해주기 위해서.
- mount 명령어 필요.
prompt> mount -t ext4 /dev/sda1 /home/users- /home/users 디렉토리를 통해 /dev/sda1 접근
File System Implementation
How to implement a Simple File System
- File system is pure software
- CPU/memory virtualization은 특별한 하드웨어 기능을 썼다.
- CPU: timer interrupt, processor mode
- memory: 주소 변환, Multi-level page table
- File System을 위한 별도의 기능은 없다.
- Data structures
- disk는 block들로 구성된 block device
- 이걸로 file / directory라는 abstraction을 제공해야 한다.
- 데이터와 메타데이터를 어떻게 제공할 것인가?
- Access Methods
- open(), read(), write() 와 같은 시스템 콜과의 Interaction
- CPU/memory virtualization은 특별한 하드웨어 기능을 썼다.
- File system is pure software
Overall Organization
- Blocks
- 디스크의 block이 아니고, 파일 시스템 관점에서의 block. (이하 하드웨어적 block은 sector라 한다.)
- 일반적으로 여러개의 sector를 포함할 수 잉ㅆ는 크기로 정의.
- 디스크를 가상적으로 같은 크기의 block으로 나눈다
- Data region
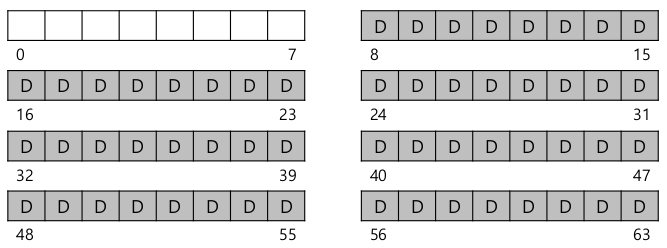
- 데이터들이 들어가기 위한 block들이 모여있는 data region.
- 디렉토리도 포함.
- 1칸이 block. 회색부분 data region. 0~7: 다른 용도로 비워놨다.
- Metadata
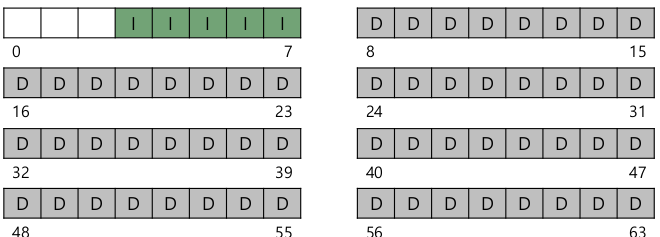
- 각가의 file들에 대한 정보를 저장
- 어떤 데이터 block을 가지고 1 파일을 구성하는가.
- 파일 크기 / 접근 권한 / 언제 접근했는지 시간정보 저장
- inode (index node)
- metadata 저장
- disk의 특정 공간을 inode table로서 reserve
- inode 하나는 block크기만큼 필요하지 않다. 1개의 block 안에 여러개의 inode 존재
- 각가의 file들에 대한 정보를 저장
- Allocation structures
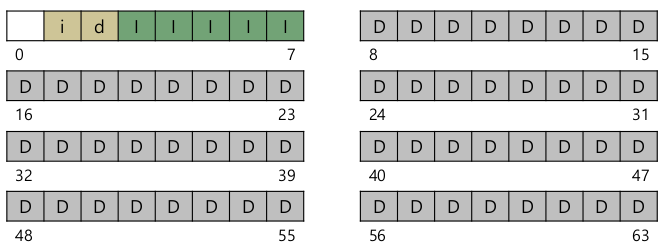
- inode는 파일마다 하나씩. inode에 해당파일을 구성하는 data block이 명시되어 있다.
- file을 생설할 때 마다 inode 공간 할당, data를 위한 block 할당.
- 메모리처럼 freelist가 필요하다.
- Superblock
- 전체 파일시스템 정보 포함
- inode 몇개, data block 몇개, inode table 시작 / 끝지점 등
- mounting 할 때 OS는 superblock을 읽고 freelist, inode table, data region을 위한 변수를 읽는다. OS가 포맷을 알고 있어야 한다.
- Blocks
Example
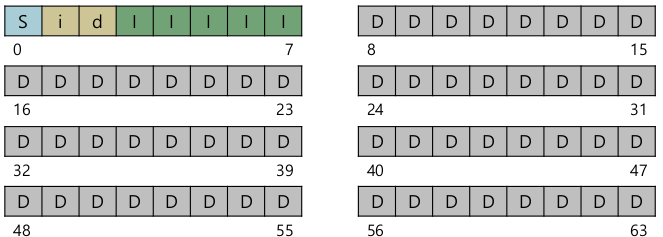
- Block size: 4KB
- 페이지 사이즈와 동일, 하드웨어 sector는 512bytes이므로 1 block = 8 sector
- 256 KB partition이라 할때 64-block partition.
- inode size: 256 B
- block당 16 inode. 5개 inode block이므로 총 80개의 inode
- 실제로 data block은 56개 뿐이므로 80개까지 존재하긴 어렵다.
- Block size: 4KB
inode
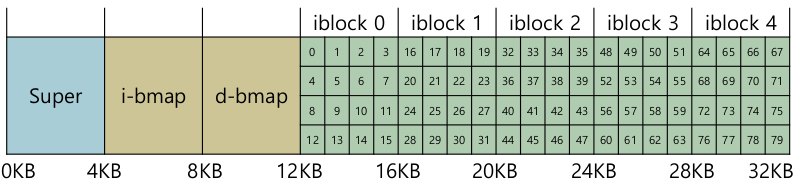
- i-number
- 각 inode는 숫자로 접근된다.
- inode number -> inode table entry
- To read inode number 32
- offset 계산. 32 * sizeof (inode) = 8 KB. 시작 지점에서 8KB만큼 떨어진 곳
- inode-table 시작지점: 12 KB
- 8 KB + 12 KB = 20 KB
- Disk sector 단위다. byte addressable이 아님.
- 보통 512 bytes.
- Sector address: (20 * 1024) / 512 = 40
- 읽어드린 40번 sector 안에는 다른 정보가 있을수도 있겠다. (inode 사이즈는 256 B, sector는 512 B)
- How the inode refers to Where Data Blocks are
- Multi-level index
- inode 에는 이 데이터파일을 구성하기 위한 Data block들이 어디어디 있다 정보 => direct pointer / indirect pointer
- direct pointer
- 파일을 구성하는 data block 을 가리킨다. 포인터 개수가 무한정 있을 수 없다. => 큰 파일 지원이 어렵다.
- indirect pointer
- data block을 가리키기는 하지만 data block을 가보면 다시 여러개의 포인터들이 존재. 한번 터 다고 들어가야 데이터가 들어있는 곳을 찾을 수 있다.
- file system에 따라 1개 또는 여러개.
- 파일이 아주 커졌을 때만 indirect pointer를 써서 block 안에도 포인터를.
- 파일이 작으면 indirect pointer가 존재는 하지만 사용은 안한다.
- double indirect pointer: 가리키는 data block 안에 또 다시 indirect pointer
- example
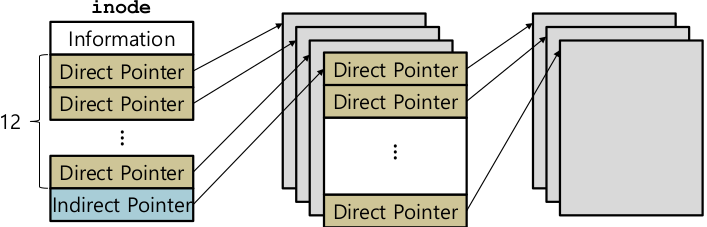
- 12 direct pointers
- 1 indirect pointer
- Block size 4KB
- 4B disk address
- 1 direct pointer: 1 block, 4KB
- 1 indirect pointer: ((4KB / 4B) + 12) blocks, 4144KB
- Multi-level index
- i-number
Directory Organization
- Directory
- 내부적으로 역시 파일처럼 관리한다.
- inode가 있고, type field에 “regular file” 대신 “directory"로 표현
- directory - direct pointer의 data block 안에는 (entry name, inode number) 존재
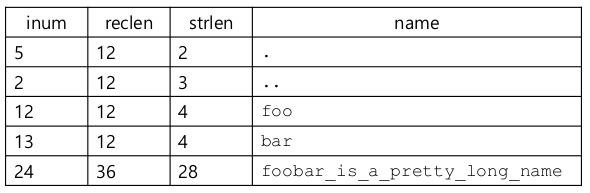
- reclen: recrod 총 길이
- 딱 맞게 하진 않고, ext4의 경우 4의 배수, name을 표함할 수 있는 가장 작은 값.
- strlen: 파일 이름 길이
- deleting a file
- record를 0으로 다 지울 것인가? -> 느리다. 메모리도 아니고 디스크.
- inode number 만 0으로. record에는 남겨둔다.
- 새로운 파일이 생겨날 때 record안에 들어갈 수 있으면 재사용.
- Directory
Free space management
- example) 파일을 생성하는 경우
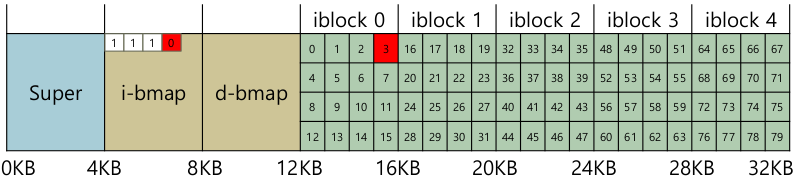
- inode 할당을 위해 i-bmap을 뒤진다. 비어있는 inode number를 가져오고, 1로 셋팅.
- 마찬가지로 data block을 위해 d-bmap을 뒤져서 비어있는 data block을 가져오고 1로 셋팅. inode에 direct pointer / indirect pointer mapping
- 경우에따라 데이터를 많이 써야한다면 d-bmap에서 이어져있는 data block을 가져오도록. (연속되어 있어야 성능이 좋을 것)
- example) 파일을 생성하는 경우
(3)
- Reading a file from disk
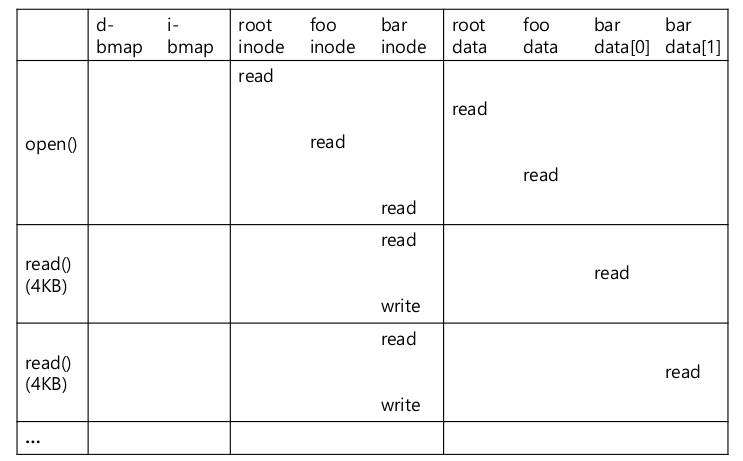
- open("/foo/bar”, O_RDONLY): /foo/bar 를 위한 inode를 찾는다.
- root를 먼저 찾아야한다.
- 일반적으로 root의 inode number는 2. 0: 지워진 파일, 1: 물리적으로 손상된, 사용할 수 없는 bad block
- data block을 읽어서 foo라는 entry를 찾는다. (inumber로 찾는다)
- foo의 inode를 찾아서 data block을 읽어서 최종적으로 bar의 inode를 알게 된다.
- bar의 inode 접근
- permission check
- file descriptor 할당, PCB 안에 저장.
- 0: stdin, 1: stdout, 2: stderr
- Returns it to the user
- root를 먼저 찾아야한다.
- read()
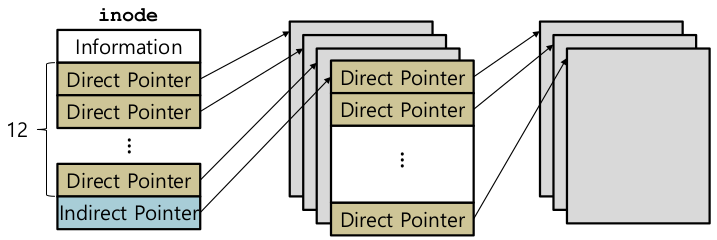
- 첫번째 block부터 읽는다.
- inode 안에 마지막 접근시간 update
- file offset update
- close()
- PCB file descriptor 반납
- I/O를 하진 않는다.
- write()
- read보다 훨씬 복잡하다. data block에 write
- 새롭게 open해서 wrtie하는 경우 write를 위한 data block 할당.
- inode도 바꿔야 하고, bitmap도 바꿔야 한다.
- 5가지 I/O가 발생
- data bitmap을 찾아서 free datablock을 찾는다.
- bitmap update
- inode를 읽어오고, write 후 update
- 실제 data block에 쓰기작업
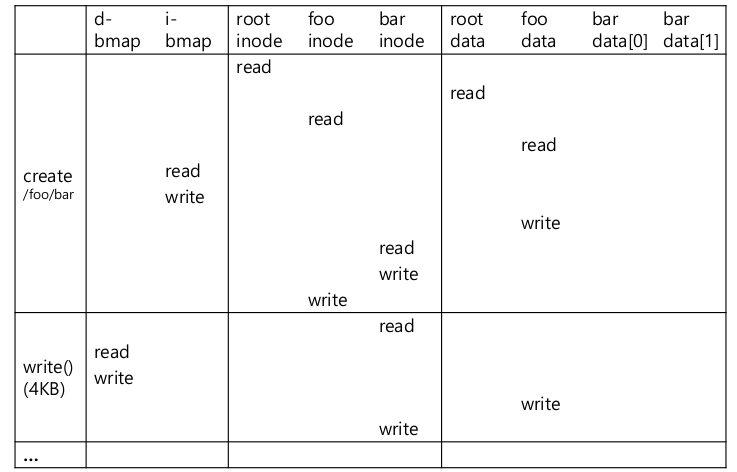
- 그림에서 write()부분이 foo가 아니라 bar임
- open("/foo/bar”, O_RDONLY): /foo/bar 를 위한 inode를 찾는다.
- Caching and Buffering
- 파일 read / write후 많은 I/O를 야기, 느리다. 성능에 있어서 문제가 된다.
- page cache
- write가 일어날 때 buffering 하는 공간. 자주 읽을 것 같은 data block을 메모리에 계속 갖는다.
- CPU 하드웨어 캐시는 아니고, data block / inode block을 메모리에 저장, 기능 자체가 cache와 동일.
- cache 하는 단위가 page 크기: 메모리 안에 효과적으로 저장
- ex) read에 있어서도 inode 접근은 여러번 한다. 메모리에 있는 inode 를 읽어서 read / write 성능 향상
- Write buffering
- 디스크에 바로 쓰지 않고 메모리에 갖고 있는다. 모아서 I/O Request
- disk schdule에 효과적
- 같은 여역에 대해 여러번 wrtie 한 경우 마지막 것만. write 수를 줄일 수 있다.
- 문제: 최신 정보로 update가 되지 않는다. –> Journaling
FSCK and Journaling
(1)
- How to Update the disk despite crashes
- They system may crash or lose power between any two writes
- write operation에 대한 요청이 있었는데, 갑자기 power가 꺼진다.
- 언제 발생할 지 예측할 수 없다.
- disk write에 대해선 부분적으로만 완료된 상태?
- 컴퓨터를 다시 키고, 해당 디스크 파티션을 다시 마운트 하려 할 때 inode, data block, bitmap 일관성이 깨질 수도. 데이터 손실 가능성 존재
- How do we ensure the file system keeps the on-disk image in a reasonable state?
- File system checker (fsck)
- Journaling
- They system may crash or lose power between any two writes
- Example
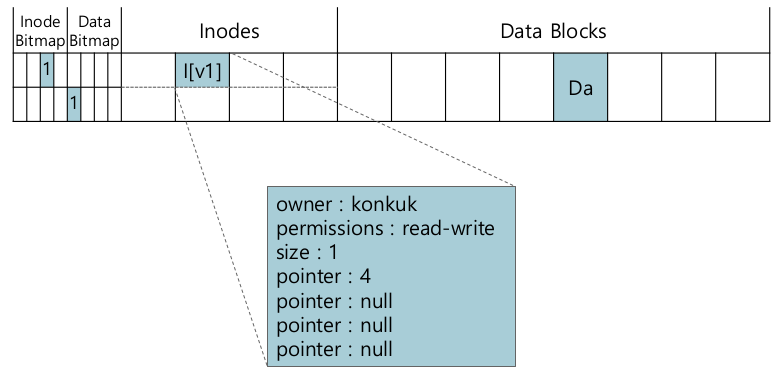
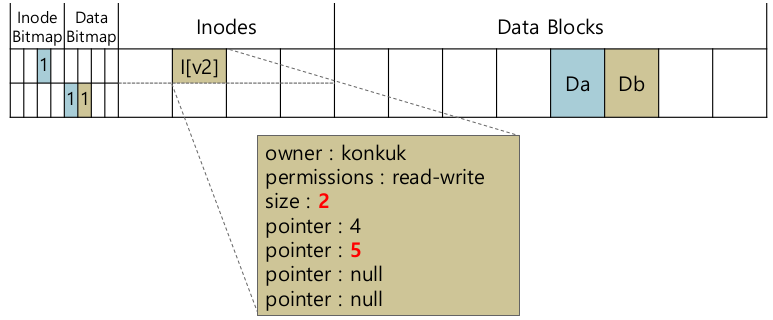
- data block을 추가하는 경우
- file open
- lseek 해서 마지막으로 옮기고
- 4KB write 하고 close
- 데이터는 연속적이지 않을 수 있다. 가급적이면 연속
- Three writes: data bitmap, inode, data block
- 물리적으로 디스크에 써지는 순서는 바뀔 수 있다. 언제 어느것이 오류날 지 모른다.
- Crash scenarios (only a single write succeed, 하나만 성공한 케이스)
- Just the data block
- 전혀 인지하지 못한다. 연결이 안되어 있으니
- 파일이 깨지진 않았다. mount가 안된다던지 하는 문제가 없다.
- Just the inode
- garbage data가 있을 것. 제대로 된 데이터를 읽지는 못한다.
- File-system inconsistency 발생.
- Just the bitmap
- File-system inconsistency
- bitmap엔 사용한다고 표시가 되어 있는데, 해당 block을 direct point로 가리키는 inode는 존재하지 않음.
- garbage를 접근하는 일은 없다. 그저 space leak.
- Just the data block
- Crash scenarios (two writes succeed; one fails)
- inode와 bitmap 성공, data 실패
- file system 관점에선 inconsistency가 존재하지 않음.
- 하지만 garbage를 가리키게 된다.
- inode와 data 성공, bitmap 실패
- inode와 bitmap 간 정보가 달라진다.
- File-system inconsitency.
- 해당 데이터 블락을 bitmap에 의해 다른 파일을 위해 할당하게 되는 문제점
- bitmap과 data 성공, inode 실패
- File-system inconsistency.
- inode에선 해당 데이터를 인지하지 못하고, 해당 데이터 블락은 실제론 어떤 inode에서도 사용하고 있지 않음.
- bitmap에선 사용한다고 표기 -> memory leak
- inode와 bitmap 성공, data 실패
- data block을 추가하는 경우
(2)
- fsck
- Unix 계열 운영체제 도구
- file system의 일부는 아니고 file system의 내용을 이해해서 inconsistency를 해결해주는 도구
- inconsistency 상황이 발생하는지 확인
- 모든 문제를 해결할 수는 없다. (잃어버린 data를 찾아주진 못한다.)
- 최대한 consistent 하게 만들어준다. mount, 향수 사용에 있어서.
- What fsck does. fsck가 수집하는 내용
- Superblock
- disk partition에 있는 superblock을 보고 해당 정보들이 reasonable 한지 확인.
- Free blocks
- inode의 direct pointer / indirect pointer 사용, 어떤 data block을 사용하고 있는지 분석
- 자주 사용하고 있다는 data block들이 bitmap에 제대로 표현이 되어 있는지.
- write operation 중 inconsistency가 발생한 경우 이를 해결하기 위해 노력한다.
- bitmap에선 1, 가리키는 inode 없음
- inode pointer 존재, bitmap에선 0
- inode states
- inode의 여러 metadata들이 알맞은 값을 갖고 있는지
- ex) type -> regular file, directory, symbolic link. 가령, 정의되지 않는 값을 갖고 있다.
- 발견되면, 해결하기 어려우므로 해당 inode를 지운다. inode bitmap도 해제.
- inode의 여러 metadata들이 알맞은 값을 갖고 있는지
- inode links
- 같은 inode를 공유하는데, 다른 이름의 파일이 여러개 있을 수 있다. 공유하고 있음을 명시하기 위해 reference count
- 이 refernce count가 맞는지 확인
- Duplicates
- 서로 다른 inode가 동일한 data block을 가리킬 경우
- 둘 중 한 inode를 지우거나, 해당 data block을 copy, inode pointer update
- Bad block pointers
- pointer가 partition 내 data block을 가리키는지 확인
- 이 disk partition 이 갖고 있지 않는 번호를 가리킨다 => bad block pointer
- 해당 pointer 값을 사용하지 않도록 초기화.
- Directory 확인
.,..을 갖고 있는지.- directory entry에 있는 각 inode가 실제 존재하는 file과 directory에 문제 없이 연결되는지.
- 단점
- 상당히 느리다.
- 해당 디스크 파티션 안에 존재하는 모든 superblock, bitmap, inode 정보, data block 들과의 연결관계 모두 뒤져봐야한다.
- disk volume이 상당히 크다면, 크게는 몇시간 까지 걸릴 수 있다.
- Wasteful.
- write operation 문제가 발생하는것은 전원이 나간 시점에 발생한 blocks, inodes, bitmap.
- 작은 문제 해결을 위해 disk partition 전체를 봐야한다.
- 상당히 느리다.
- Superblock
(3)
Journaling (Write-Ahead logging)
- Journaling
- 디스크 update 하기 전에 note. 기록을 남겨 놓는다.
- Checkpointing
- 우리는 checkpointing 안하고 있었다. 실제 data update
- Journaling이 되었을 때 disk의 저장 구조는?
- Journaling
Ext3
- on-disk structures
- Disk를 block group으로 나누다.
- 각 block group은 inode bitmap, data bitmap, inode, data block 포함
- Journal

- on-disk structures
Data Journaling
- Example

- TxB: Transaction 시작, TxE: Transaction 끝
- Writing the journal
- 차례로 다 써질때 까지 기다린다? TxB -> I -> B -> Db -> …
- 상당히 느리다.
- 5가지를 한꺼번에 다 write?
- Disk scheduling -> reordering
- 전원이 나갈경우 crash. reboot시 garbage …
- 두 단계로 이루어진다.
- Step 1: TxB, I, B, Db 까지만 한꺼번에. 위치는 그대로지만 순서는 Disk Scheduling algorithm으로 결정.
- Step 2: Step1이 다 끝난 후에 TxE write
- TxE를 쓰다가 전원이 나가서, 부적합 정보가 쓰여지면 문제 발생.
- 일반적으로 TxE는 1 sector (512 bytes)의 크기를 갖도록 한다.
- Disk는 512 byte write에선 성공 / 실패를 보장 -> atomic
- 차례로 다 써질때 까지 기다린다? TxB -> I -> B -> Db -> …
- Recovery
- Transaction이 다 쓰여지지 않았다.
- 해당 update 무시. Journal 안 데이터만 날라간다.
- File system consistency 보장
- Journal은 다 쓰여졌는데, Checkpointing이 되지 않은 채 전원이 나감
- Journal을 계속해서 Journal Group 부분에 적는다.
- Journal을 통해 복구 가능
- 해당 Journal 들을 순서대로 reply -> 다시 반영
- 복구는 가능. 문제는 이미 checkpointing이 되어 있는 Journal이 남아서 불필요하게, redundant하게 실행해서 성능저하 가능성
- Transaction이 다 쓰여지지 않았다.
- Batching log updates
- Problem: extra disk traffic
- ex) 같은 directory에 file 2개. 이 2개의 file의 inode는 동일하다. 동일한 block에 inode를 쓰기위한 write …
- traffic이 2배, 성능저하.
- Solution: Buffering
- 동일한 block에 대해서 update하려는 시도가 연속적. 이를 묶어서 한번에! traffic을 줄일 수 있다.
- Problem: extra disk traffic
- Making the log finite
- Problem: log(Journal) 공간은 한정적
- 공간을 아주 크게 만들면 recovery에 긴 시간이 걸린다.
- 공간을 줄이면 내용 유실, 반영까지 다음 Journal 기록 불가.
- Solution: Circular log (Circular queue)

- 환형 구조이므로 제한적 공간에서도 효율적으로 사용 가능.
- Problem: log(Journal) 공간은 한정적
- Ordered Journaling (=Metadata Journaling)
- Problem: Data Journaling
- 어떤 데이터를 쓸지도 Journaling에 포함. 가장 큰 부분이다.
- Solution: Metadata Journaling

- 데이터는 Journal에 포함하지 말자.
- Crash가 발생했을 땐? data를 언제 disk에 쓸것인가?
- ext3는 Journaling 하기 전에 먼저 data를 쓴다.
- 그 다음 Journal에 metadata를 쓴다.
- 데이터만 쓰고 crash -> 복구 X.
- 데이터 + Transaction -> inode, bitmap 만 조절해서 recover 가능.
- Protocol
- Data write: 데이터 블락에 쓴다.
- Journal metadata write: TxB, I, B
- Journal Commit: TxE
- Checkpoint metadata
- Free
- Problem: Data Journaling
- Example
QnA
- 리눅스를 분석해보고 싶은데요…. 익숙한 System call의 커널 entry point를 시작으로 내부 구현 코드를 추적해보자
- 운영체제를 구현해보고 싶은데요…. RTOS 구현 from scratch.
